Skalieren Sie Analysen von unstrukturiertem Text mit effizienter Batch-LLM-Inferenz

Unstrukturierter Text ist überall im Geschäft: Kundenrezensionen, Supporttickets, Anrufprotokolle, Dokumente. Large Language Models (LLMs) transformieren die Art und Weise, wie wir Nutzen aus diesen Daten ziehen, indem wir Aufgaben von der Kategorisierung bis zur Zusammenfassung ausführen und vieles mehr. Während KI bewiesen hat, dass Echtzeit-Gespräche in natürlicher Sprache mit LLMs möglich sind, kann das Extrahieren von Erkenntnissen aus Millionen unstrukturierten Datensätze mithilfe dieser LLMs ein Gamechanger sein. Hier wird Batch-LLM-Inferenz unerlässlich.
In diesem Beitrag erhalten Sie Einblicke in gängige Geschäftsanwendungsfälle für umfangreiche Textdatenanalysen. Sie erfahren außerdem, warum die Bereitstellung von Batch-LLM-Pipelines eine Herausforderung darstellen kann und wie Snowflake Snowflake Cortex AI für die Batch-Inferenz über SQL-Funktionen optimiert hat.
Was sind gängige Batch-LLM-Inferenzjobs?
Verschiedene Teams in einem Unternehmen können Batch-LLM-Inferenz nutzen, um Erkenntnisse aus großen Textdatenmengen zu gewinnen. Customer-Intelligence-Teams analysieren Bewertungen und Forumskommentare, um Stimmungstrends zu erkennen, während Supportteams Tickets verarbeiten, um Produktprobleme aufzudecken und Lücken in einer Produkt-Roadmap aufzudecken. Gleichzeitig nutzen Betriebsteams Entitätenextraktion aus Dokumenten, um Arbeitsabläufe zu automatisieren und metadatengestützte analytische Filter zu ermöglichen. Hier einige weitere Beispiele, wie verschiedene Teams mit LLMs Erkenntnisse aus großen Mengen unstrukturierter Textdaten gewinnen können:
Textklassifizierung und Tagging: Automatische Kategorisierung von Supporttickets, E-Mails, Nachrichtenartikeln oder Produktbewertungen nach Stimmung, Thema oder Dringlichkeit.
Entitätenextraktion: Extrahieren von wichtigen Entitäten (Namen, Daten, Standorte, Finanzzahlen) aus Verträgen, Rechnungen oder Krankenakten, um unstrukturierten Text in strukturierte Daten zu verwandeln.
Stimmungs- und Trendanalyse: Die umfassende Analyse von Kundenfeedback, Umfrageantworten oder Social-Media-Diskussionen, um Trends zu erkennen, Stimmung zu messen und Geschäftsentscheidungen zu treffen.
Inhaltsmoderation: Scannen großer Datasets (Social-Media-Beiträge, Chatprotokolle, Kundenfeedback) auf Richtlinienverstöße, schädliche Inhalte oder Compliance-Probleme.
Dokumentenzusammenfassung: Erstellung prägnanter Zusammenfassungen für umfangreiche Berichte, Forschungsarbeiten, Rechtsdokumente oder Sitzungsprotokolle.
Dokument RAG-Vorbereitung: Erfassen, Bereinigen und Stapeln von Dokumenten, bevor sie in Vektordarstellungen eingebettet werden. Das ermöglicht effizientes Abrufen und verbesserte LLM-Antworten in RAG-Systemen (Retrieval-Augmented Generation).
Textdatenqualität: Validierung mehrerer Textfelder, wie z. B. Formularfüllungen, indem Kontext für ideale Eingabekombinationen angegeben wird. So können LLMs Anomalien und falsche Datensätze erkennen und die Datenqualität verbessern.
Feature Engineering: Extrahieren, Kategorisieren und Umwandeln von unstrukturiertem Text in strukturierte Features, Erweiterung von ML-Modellen um angereicherten Kontext und Einblicke.
Warum effiziente Batch-LLM-Pipelines wichtig sind
„LLMs verändern den Arbeitsplatz“ ist mehr als nur ein Slogan. Bedenken Sie Folgendes: Die Kategorisierung von 10.000 Supporttickets würde selbst für Ihre schnellste Mitarbeiterin etwa 55 Stunden (bei 20 Sekunden pro Ticket) dauern. Mit einer optimierten LLM-Pipeline dauert die gleiche Aufgabe Minuten. Dies ist keine schrittweise Verbesserung – es ist ein transformativer Effizienzgewinn, der Tausende von Arbeitsstunden spart und die Reaktionszeiten drastisch beschleunigt.
Wenn das Datenvolumen wächst und die KI-Automatisierung zunimmt, hängt die Kosteneffizienz bei der Verarbeitung mit LLMs sowohl von der Systemarchitektur als auch von der Modellflexibilität ab. Ein effizientes Stapelverarbeitungssystem kann kostengünstig skaliert werden, um wachsende Mengen unstrukturierter Daten zu bewältigen. Die Möglichkeit, LLMs flexibel zu wechseln, hilft Unternehmen bei der Kostenoptimierung, indem sie die Modelle für jeden Anwendungsfall richtig dimensioniert und je nach Modellverbesserung einfach aufrüstet.
Und um eine erhebliche Technologie- und Teameffizienz zu schaffen, müssen Unternehmen Möglichkeiten in Betracht ziehen, LLM-Pipelines in bestehende strukturierte Datenworkflows zu integrieren. Die Ausweitung bestehender Investitionen in die Bereiche Pipeline-Management, -Verarbeitung und -Orchestrierung vereinfacht die Architektur und reduziert die betriebliche Komplexität aufgrund von Integrations- und Infrastrukturwartungsarbeiten. Diese Vereinheitlichung versetzt auch Data Engineers, die bereits strukturierte Pipelines verwalten, in die Lage, Workflows für unstrukturierte Daten problemlos zu onboarden und zu pflegen.
Batch-Inferenz-Pipelines effizient ausführen mit Cortex AI
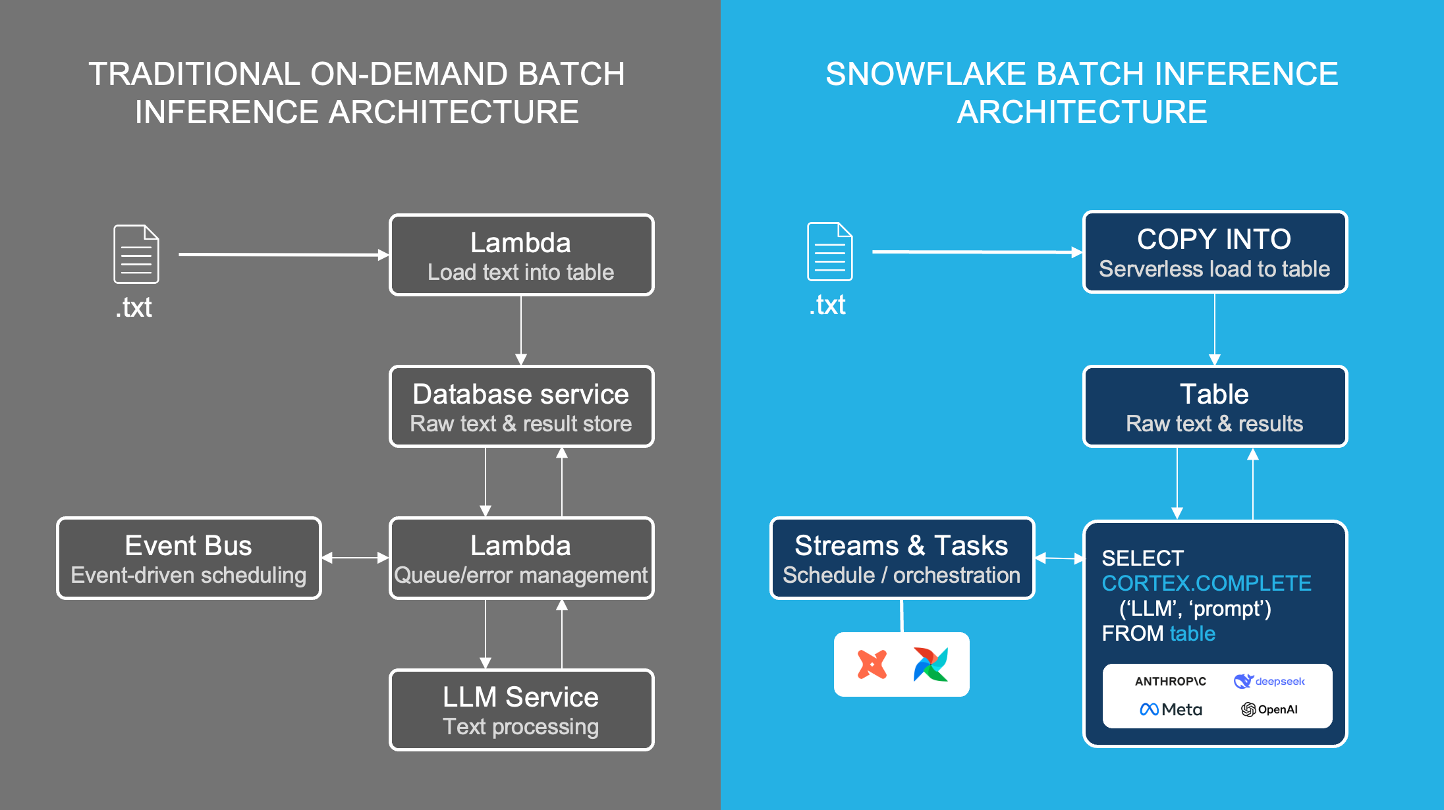
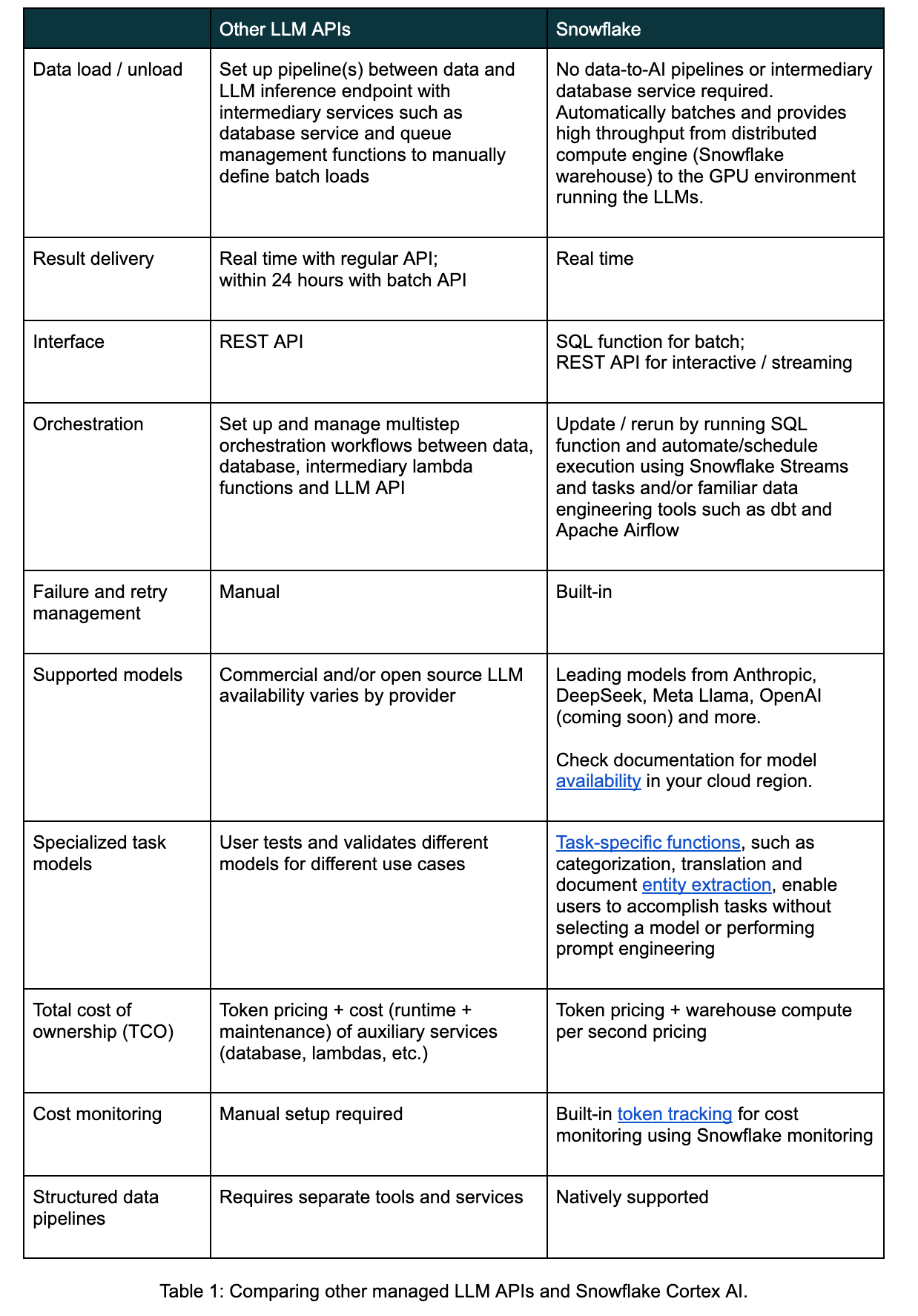
Headset wechselte eine der Batch-Kategorisierungs-Pipelines, die zuvor bei einem führenden LLM-API-Inferenzanbieter (Fireworks AI) ausgeführt wurde, und reduzierte die Auftragsausführungszeit mithilfe der Snowflake Cortex COMPLETE-Inferenzfunktion von 20 Minuten auf 20 Sekunden.
Mit der Snowflake Cortex COMPLETE-Funktion können Entwickler:innen Batch-LLM-Inferenzen mit SQL-Funktionen ausführen, die keine zwischengeschalteten Datenbanken oder Lambdas erfordern, um eine zuverlässige Verarbeitung mit hohem Durchsatz und flexibler Modellwahl zu erreichen.
Weitere Kundenerfolge
Durch den Einsatz von Snowflake beschleunigte Nissan seine Projektlaufzeit um zwei Monate für eine Customer-Intelligence-Anwendung, die die Kundenstimmung aus Bewertungen und Foren analysiert, um Händler bei der Erweiterung ihres Produkt- und Serviceangebots zu unterstützen. On-Demand-Webinar ansehen.
Skai stellte in nur zwei Tagen ein Kategorisierungstool bereit, um seiner Kundschaft durch die Entwicklung von Kategorien, die über mehrere E-Commerce-Plattformen hinweg sinnvoll sind, bessere Einblicke in Kaufmuster zu ermöglichen. Customer Story lesen.
Weitere Geschichten finden Sie in unserem Customer Success E-Book.
Jetzt entdecken
Sehen Sie sich diese Ressourcen an und informieren Sie sich über Updates zur serverlosen Inferenz für weitere Datentypen.
Autor:innen

