Datensilos aufbrechen: skalierbare Entwicklung und Bereitstellung von Modellen mit Snowflake ML

Trotz der Bemühungen vieler ML-Teams gelangen die meisten Modelle aufgrund unterschiedlicher Tools immer noch nicht in die Produktion, was oft zu fragmentierten Daten- und ML-Pipelines und einem komplexen Infrastrukturmanagement führt. Snowflake hat sich kontinuierlich darauf konzentriert, fortschrittliche Modelle für Kunden einfacher und schneller in Produktion zu bringen. 2024 haben wir über 200 KI-Funktionen eingeführt, darunter eine vollständige Suite von End-to-End-ML-Funktionen in Snowflake ML, unserem integrierten Funktionsumfang für die Entwicklung, Inferenz und Operationalisierung von ML-Modellen. Wir freuen uns, dieses Jahr die Dynamik mit der Ankündigung fortzusetzen, dass die folgenden Funktionen für GPU-gestützte ML-Workflows jetzt allgemein für Produktions-Workloads verfügbar sind:
Entwicklung: Snowflake Notebooks in Container Runtime – jetzt allgemein verfügbar in AWS und als Public Preview in Azure – optimiert das Laden von Daten und verteilt Modelltraining und Hyperparameteranpassung auf mehrere CPUs oder GPUs in einer vollständig verwalteten Containerumgebung, die innerhalb Ihres Snowflake-Sicherheitsrahmens mit sicherem und sofortigem Zugriff auf Ihre Daten ausgeführt wird. Snowflake ML unterstützt jetzt auch die Möglichkeit, synthetische Daten zu generieren und zu verwenden, jetzt in Public Preview.
Inferenz: Model Serving in Snowpark Container Services, jetzt allgemein verfügbar in AWS und Azure, bietet eine einfache und performante verteilte Inferenz mit CPUs oder GPUs für jedes Modell, unabhängig davon, wo es trainiert wurde.
Monitoring: ML Observability, jetzt allgemein in allen Regionen verfügbar, bietet integrierte Tools zur Überwachung und Alarmierung von Qualitätsmetriken wie Performance und Drift für Modelle, die Inferenz in Snowflake ausführen oder speichern.
Governance: ML-Objekte und Workflows sind vollständig in die Governance-Funktionen von Snowflake Horizon integriert, einschließlich Daten und ML Lineage, jetzt allgemein verfügbar.
Zwischen November 2024 und Januar 2025 nutzten jede Woche über 4.000 Kunden die KI-Funktionen von Snowflake. Eines dieser Kundenunternehmen ist Scene+, ein großes Kundenbindungsprogramm in Kanada, das Snowflake ML einsetzt, um seine ML-Workloads zu optimieren und zu verbessern.
„Snowflake ML hat die Einführung von ML-Modellen in die Produktion bei Scene+ entscheidend verändert. Wir haben die gesamte plattformübergreifende Datenbewegung eliminiert, Projektlaufzeiten verkürzt und die Kosten durch die Nutzung der End-to-End-Funktionen von Snowflake ML, einschließlich Notebooks, Feature Store, Modellregistrierung und ML-Beobachtbarkeit, gesenkt. Durch die Erstellung und Bereitstellung von Modellen in Snowflake ML hat Scene+ die Produktionszeit um über 60 % verkürzt und die Kosten für über 30 Modelle um mehr als 35 % gesenkt.“
Chris Kuusela

Entwicklung
Snowflake Notebooks in Container Runtime sind speziell für die groß angelegte ML-Entwicklung ohne Infrastrukturmanagement oder Konfiguration mit wettbewerbsfähiger Trainingsleistung entwickelt.
Beim Training mit Standardeinstellungen für Snowflake Notebooks in Container Runtime zeigen unsere Benchmarks, dass der verteilte XGBoost auf Snowflake für Tabellendaten über zweimal schneller ist als eine verwaltete Spark-Lösung und ein konkurrierender Cloud-Dienst. Bei Bilddaten führte die Ausführung von verteiltem PyTorch auf Snowflake ML auch mit Standardeinstellungen zu einer über 10-mal schnelleren Verarbeitung für ein 50.000-Bilder-Dataset im Vergleich zur selben verwalteten Spark-Lösung. Durch den Einsatz von Snowflake ML verbringen Data Scientists und ML Engineers deutlich weniger Zeit mit der Infrastruktur und Skalierbarkeit und können mehr Zeit in die Entwicklung und Optimierung ihrer ML-Modelle stecken und sich auf schnelle Geschäftsauswirkungen konzentrieren.
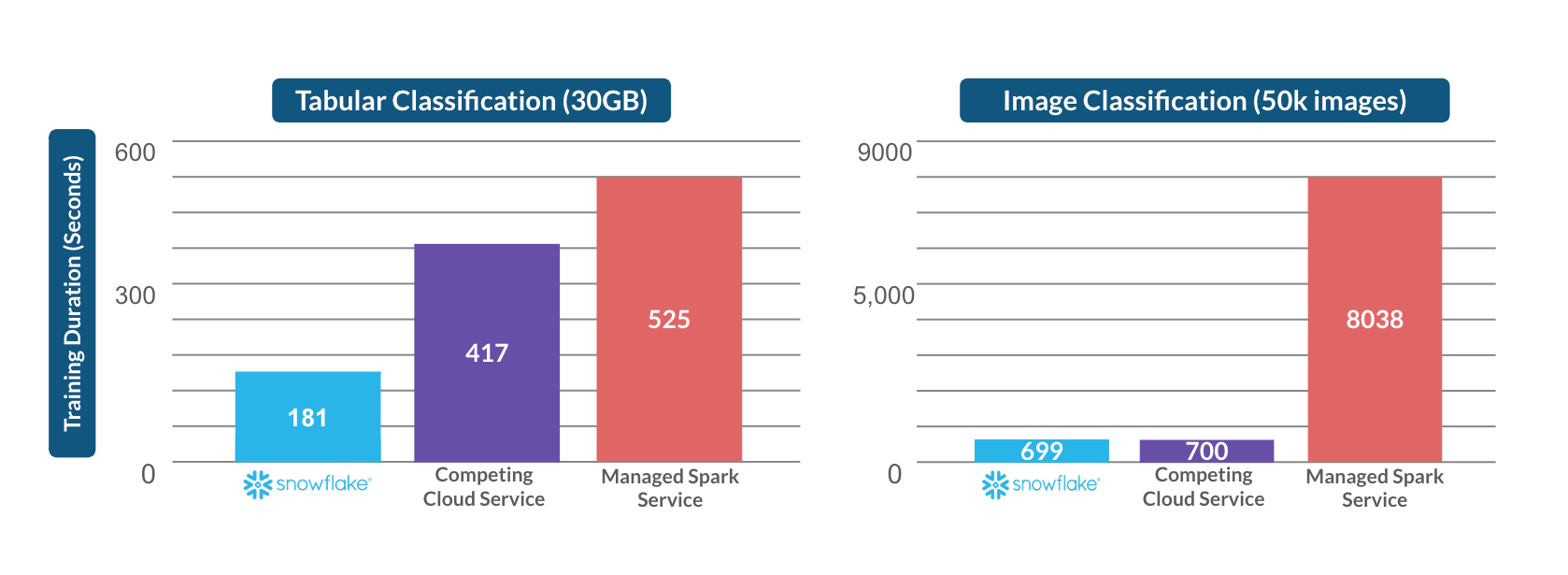
Container Runtime abstrahiert in wenigen Klicks das Infrastrukturmanagement und beschleunigt das ML-Training, indem es Folgendes bereitstellt:
Eine einfache Notebookkonfiguration zur Auswahl eines Rechenressourcenpools, sodass Data Scientists aus CPU- oder GPU-Pools auswählen können, um die Anforderungen ihrer Trainingsaufgaben zu erfüllen. Alle Kundenkonten haben automatisch Zugriff auf standardmäßige CPU- und GPU-Rechenressourcenpools, die nur während einer aktiven Notebook-Sitzung genutzt und bei Inaktivität automatisch gesperrt werden. Weitere Details finden Sie in der Dokumentation.
Eine Reihe von CPU- und GPU-spezifischen Images, vorinstalliert mit den neuesten und beliebtesten Bibliotheken und Frameworks (PyTorch, XGBoost, LightGBM, scikit-learn u. v. m.), die die ML-Entwicklung unterstützen. So können Data Scientists einfach ein Snowflake Notebook einrichten und direkt mit ihrer Arbeit beginnen.
Sicherer Zugriff auf Open-Source-Repositorys per Pip und die Möglichkeit, jedes Modell von Hubs wie Hugging Face einzubinden (siehe Beispiel hier).
Optimierte APIs für die Datenerfassung mit effizienter Materialisierung von Snowflake-Tabellen als Pandas oder PyTorch DataFrames. Daten werden effizient parallel erfasst und durch Parallelisierung über mehrere CPUs oder GPUs hinweg als DataFrame im Notebook angezeigt. Weitere Details finden Sie in der Dokumentation.
Verteiltes Modelltraining und verteilte Hyperparameteroptimierungs-APIs, die die bekannten Open-Source-Schnittstellen von XGBoost, LightGBM und PyTorch erweitern, aber die Verarbeitung auf mehrere CPUs oder GPUs verteilen, ohne dass die zugrunde liegende Infrastruktur orchestriert werden muss (siehe Beispiel hier).
Viele Unternehmen nutzen Container Runtime bereits, um kostengünstig fortschrittliche ML-Anwendungsfälle mit einfachem Zugriff auf GPUs zu entwickeln. Zu den Kunden gehören CHG Healthcare, Keysight Technologies und Avios.
CHG Healthcare
CHG Healthcare, ein Personaldienstleister mit über 45 Jahren Branchenerfahrung, nutzt KI/ML, um Personallösungen für 700.000 medizinische Fachkräfte in 130 medizinischen Fachrichtungen bereitzustellen. CHG entwickelt und produziert seine End-to-End-ML-Modelle in Snowflake ML.
„Die Verwendung von GPUs von Snowflake Notebooks in Container Runtime hat sich als die kostengünstigste Lösung für unsere Anforderungen an maschinelles Lernen erwiesen“, so Andrew Christensen, Data Scientist, CHG Healthcare. „Wir schätzen die Möglichkeit, die parallele Verarbeitung von Snowflake mit jeder Open-Source-Bibliothek in Snowflake ML zu nutzen und so Flexibilität und Effizienz für unsere Workflows zu verbessern.“
Keysight Technologies
Keysight Technologies ist ein führender Anbieter von elektronischen Design- und Testlösungen. Mit einem weltweiten Umsatz von über 5,5 Milliarden US-Dollar und über 33.000 Kunden in 13 Branchen hält Keysight über 3.800 Patente für seine Innovationen. Keysight entwickelt mit Container Runtime skalierbare Vertriebs- und Prognosemodelle in Snowflake ML.
„Nachdem wir Snowflake Notebooks in Container Runtime getestet haben, können wir sagen, dass die Erfahrung bemerkenswert ist“, so Krishna Moleyar, Analytics and Automation for IT Global Applications, Keysight Technologies. „Die flexible Containerinfrastruktur, unterstützt durch verteilte Verarbeitung auf CPUs und GPUs, das optimierte Laden von Daten und die nahtlose Integration mit [Snowflake] Model Registry haben unsere Workflow-Effizienz verbessert.“
Avios
Avios, ein führender Anbieter von Reisepreisen mit mehr als 40 Millionen Mitgliedern und 1.500 Partnern, nutzt Snowflake Notebooks in Container Runtime, um tiefgreifendere Analyse- und Datenanalyseaufgaben mit der Flexibilität durchzuführen, die das Unternehmen benötigt.
„Ich habe die Flexibilität und Geschwindigkeit, die Snowflake Notebooks in Container Runtime bieten, sehr genossen“, so Olivia Brooker, Data Scientist bei Avios. „Ich kann meinen Code ausführen, ohne mir Sorgen machen zu müssen, dass es zu einer Zeitüberschreitung kommt oder Variablen vergessen werden. Dank der PyPI-Integration habe ich außerdem den Vorteil, dass ich eine breitere Palette von Python-Paketen verwende und meine Analyse- und Data-Science-Aufgaben flexibler mache.“
Zur Entwicklung von Modellen unter Wahrung des Datenschutzes sensibler Datasets oder zur einfachen Generierung neuer Daten zur Bereicherung des Trainings unterstützt Snowflake auch die einfache und sichere synthetische Datengeneration (Public Preview). Dies ist eine leistungsstarke Funktion, mit der Data Scientists Pipelines und Modelle auf Grundlage von Daten entwickeln können, ohne dabei sensible Attribute zu beeinträchtigen und ohne auf langwierige und umständliche Genehmigungsverfahren zu warten. Das synthetische Dataset hat die gleichen Eigenschaften wie das Quell-Dataset, wie Name, Anzahl und Datentyp von Spalten, und die gleiche oder geringere Zeilenanzahl.
Bereitstellung von Modellen in der Produktion
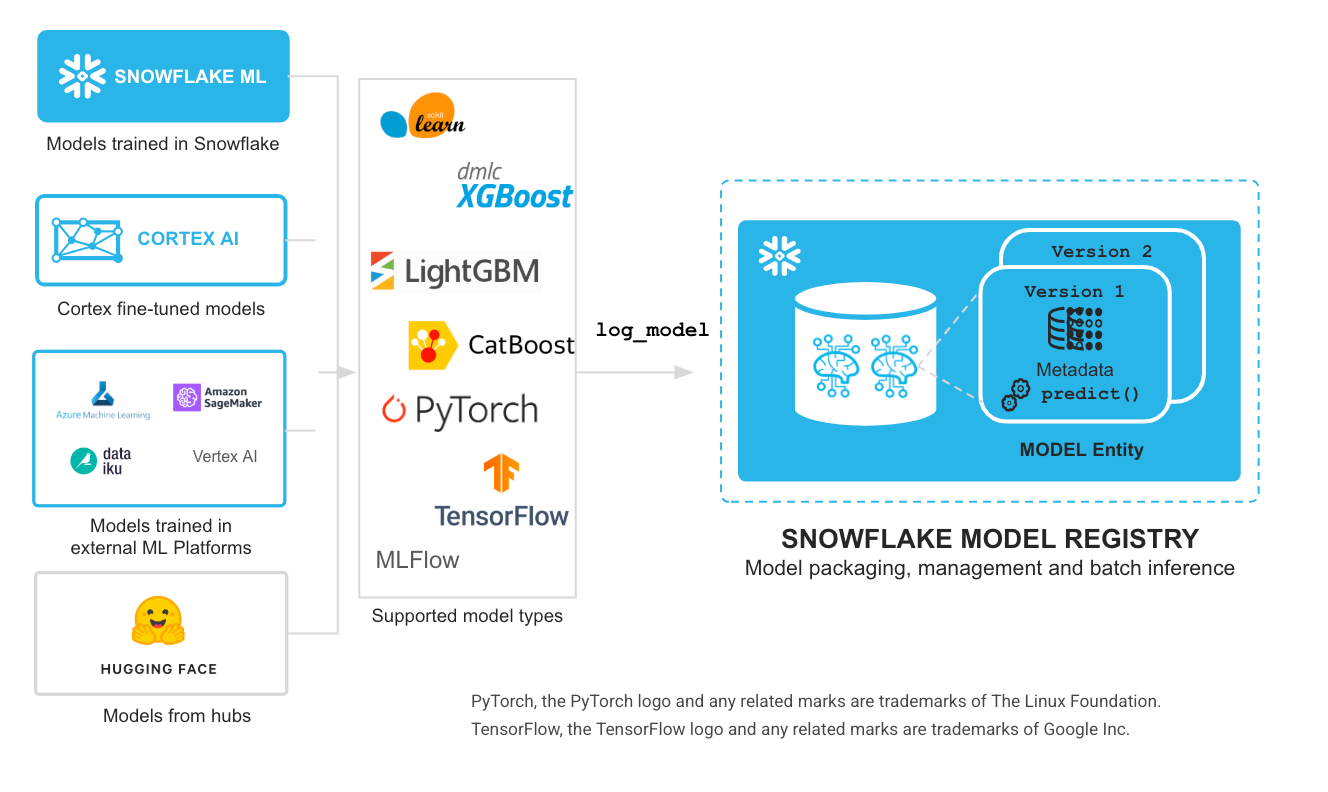
Wo auch immer sich Ihr Modell befindet: Mit Snowflake ML können Sie ganz einfach Inferenzen im Produktionsbereich durchführen und den Modelllebenszyklus mit integrierter Sicherheit und Governance verwalten. Nachdem ein Modell in der Snowflake Model Registry protokolliert wurde, kann es nahtlos mit Model Serving in Snowpark Container Services (SPCS) zur verteilten Inferenz bereitgestellt werden. Dank dieser Funktion können Ihre Inferenz-Workloads die Vorteile von GPU-Rechen-Clustern nutzen, große Modelle wie Hugging Face-Einbettungen oder andere Transformer-Modelle ausführen und beliebige Python-Pakete aus Open-Source- oder privaten Repositorys verwenden. Sie können die Modelle auch für einen REST-API-Endpunkt bereitstellen, damit Ihre Anwendungen Ihre Modellinferenz für Anwendungen mit niedriger Latenz aufrufen können (Online-Endpunkt befindet sich in der öffentlichen Prüfung). Mit Model Registry- und Inferenzlösungen können Benutzer:innen jetzt ganz einfach jedes ML-Modell verwenden, das innerhalb oder außerhalb von Snowflake trainiert wurde, mit einem der integrierten Modelltypen oder mit der benutzerdefinierten Modell-API, um jede andere Art von Modell einzubringen, einschließlich Vor- und Nachverarbeitungs-Pipelines und partitionierter Modelle, um je nach Workload-Anforderung skalierbare, verteilte Inferenz entweder in virtuellen Warehouses oder in SPCS auszuführen.
Die Jahez Group, ein Online-Anbieter für Lebensmittellieferungen mit Sitz in Saudi-Arabien, nutzt Modelle, die in SPCS bereitgestellt werden, um die Logistik zu optimieren und die Kundenzufriedenheit zu maximieren, indem die Lieferung an die Kund:innen innerhalb von 30 Minuten nach der Bestellung sichergestellt wird.
„Model Serving in Snowpark Container Services hat unseren Iterationszyklus zwischen den Modellversionen enorm unterstützt, wodurch schnelle Updates ermöglicht und Verzögerungen bei der Bereitstellung reduziert wurden“, so Marwan AlShehri, Senior Data Engineer, Jahez Group. „Dank der Unterstützung für automatische Skalierung ist die Produktion von Modellen wie immer einfach. Dank der unglaublichen Unterstützung durch das Snowflake-Team konnten wir in unserem „Estimated Time of Arrival“-Anwendungsfall eine Online-Inferenz von weniger als einer Sekunde für Echtzeitvorhersagen erreichen. Das hat zu einer besseren Zuweisung von Kurieraufträgen und einer Optimierung des Lieferprozesses geführt, wodurch wir Kosten senken und die Effizienz steigern konnten.“
Überwachung und Alarmierung
In der Produktion kann sich das Modellverhalten im Laufe der Zeit aufgrund eines unvollständigen Verständnisses der Welt in Trainingsdaten, einer Datendrift und Problemen mit der Datenqualität ändern. Änderungen an Daten oder Umgebungen können erhebliche Auswirkungen auf die Modellqualität haben.
ML-Beobachtbarkeit von Snowflake bietet die Möglichkeit, Modelle hinsichtlich Performance, Modell-Score-Drift und Feature-Value-Drift zu überwachen, wenn Inferenzen/Prognoseprotokolle in einer Snowflake-Tabelle gespeichert werden, unabhängig davon, wo das Modell trainiert oder bereitgestellt wurde. Die Überwachungsergebnisse können über Python- oder SQL-APIs abgefragt und über die mit Ihrer Modellregistrierung verbundene Benutzeroberfläche eingesehen werden, wobei Sie problemlos Warnungen auf Ihre individuellen Schwellenwerte festlegen können.
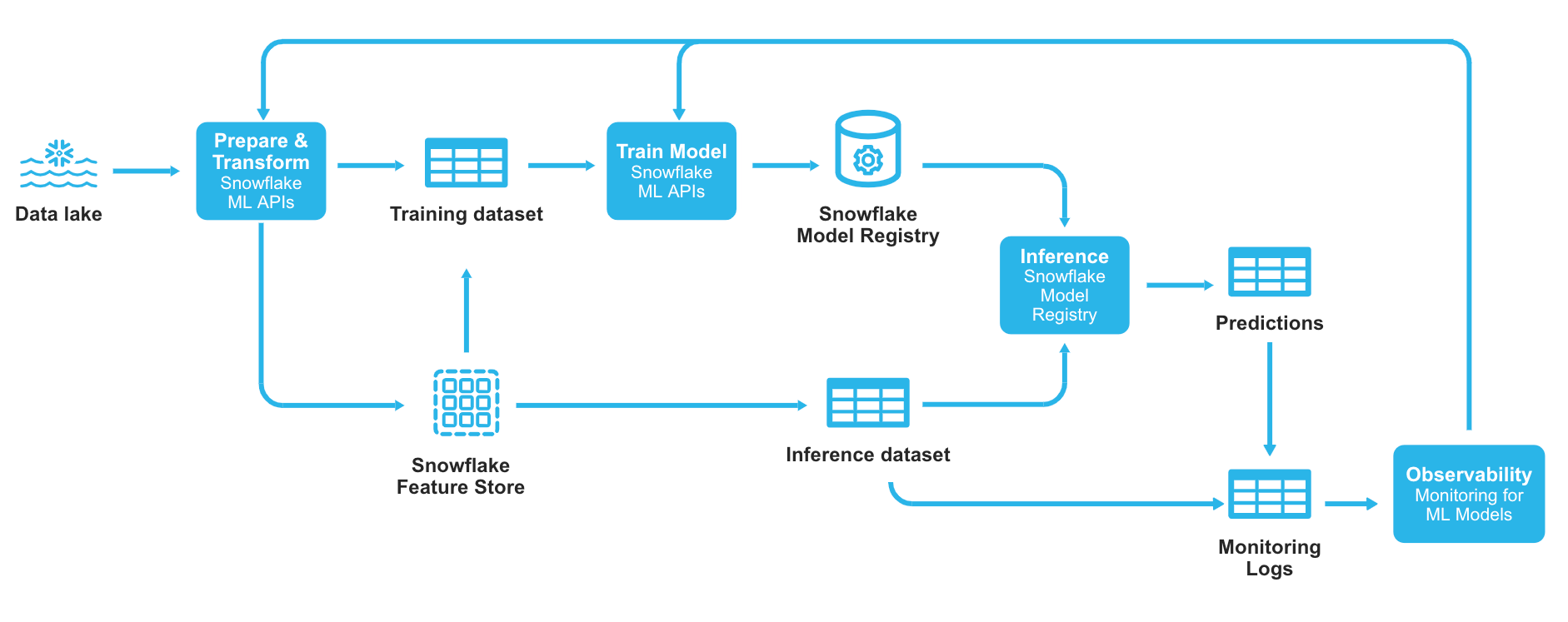
Die Storio Group, ein europäischer Marktführer für personalisierte Fotoprodukte und Geschenke, die mehr als elf Millionen Kund:innen begeistern, produziert Modelle mit integrierten MLOps-Funktionen in Snowflake, einschließlich ML-Beobachtbarkeit.
„Bei Storio haben wir in nur wenigen Monaten eine nutzbare, skalierbare und gut kontrollierte MLOps-Plattform aufgebaut, vom Konzept bis zur Produktion in Snowflake ML“, so Dennis Verheijden, Senior ML Engineer, Storio Group. „Durch die Kombination der neuen ML-Beobachtbarkeitsfunktion mit bestehenden Snowflake-Funktionen wie Dynamic Tables und ML Lineage konnten wir die Modellbeobachtbarkeit für auf unserer Plattform trainierte Modelle automatisieren. Das Ergebnis ist, dass wir für jedes bereitgestellte Modell automatisierte Dashboards haben, die die Live-Modellbewertung und -vergleich sowie Feature-Drift im Laufe der Zeit darstellen. So können sich Data Scientists auf die Wertschöpfung konzentrieren und gleichzeitig die Implementierung von Beobachtbarkeit und Überwachung auf die Plattform entladen.“
Grundlegende Governance
Das Fundament von Snowflake ML bildet die vollständige Integration mit Snowflake Horizon Catalog, der integrierten Data-Governance- und Discovery-Lösung für Compliance, Sicherheit, Datenschutz und Kollaboration. Alle Daten, Funktionen und Modelle in Snowflake werden über Clouds hinweg durch rollenbasierte Zugriffskontrollen (Role-Based Access Control, RBAC) geregelt, wodurch Unternehmen den Zugriff in großem Umfang verwalten können und der vertrauliche Zugriff auf entsprechende Geschäftsrollen eingeschränkt wird. Snowflake Model Management baut auf dieser starken Data-Governance-Grundlage auf und bietet flexible und sichere Möglichkeiten zur Verwaltung des Modelllebenszyklus in der Produktion.
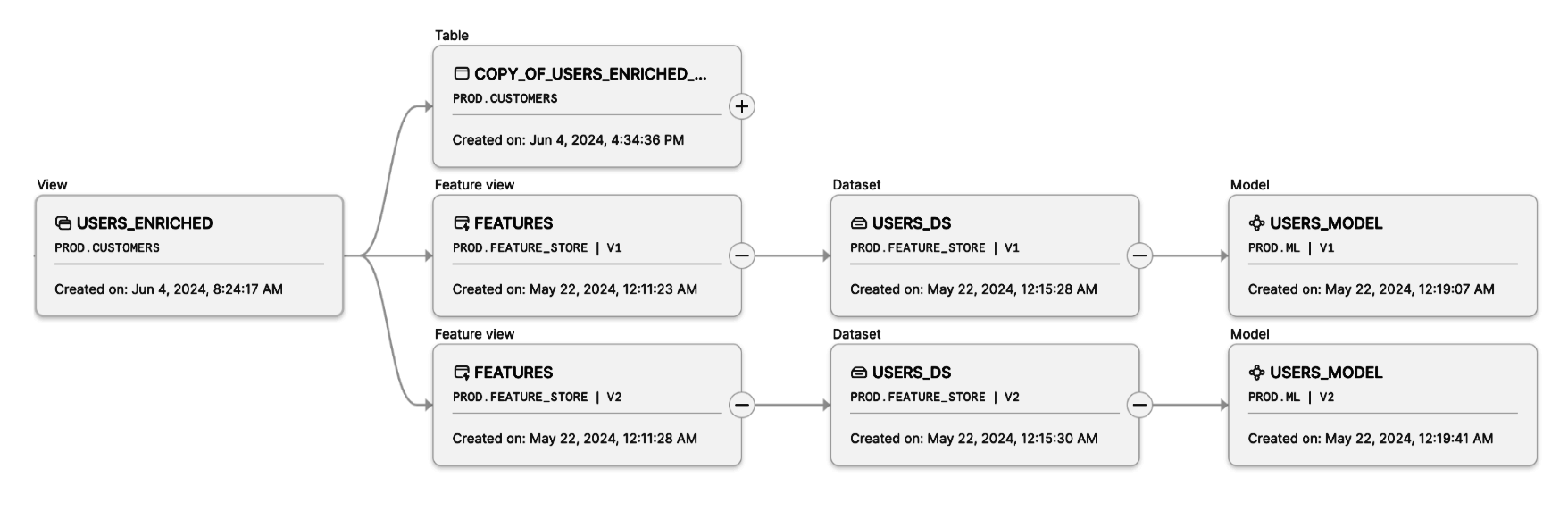
Um die vollständige Datenherkunft, den Zugriffsverlauf und die Protokolle für ML-Daten und Artefakte nachzuverfolgen, helfen die Daten und ML-Datenherkunft von Snowflake dabei, den Datenfluss von der Quelle bis zum endgültigen Ziel zu visualisieren. Der Lineage Graph unterstützt alle in Snowflake erstellten ML-Objekte – Features, Datasets und Modelle – und ermöglicht eine vollständige Rückverfolgbarkeit von ML-Pipelines. Das hilft bei der Einhaltung gesetzlicher Vorschriften und Audits sowie bei der Reproduzierbarkeit und verbesserten Robustheit von ML-Workloads.
Erste Schritte
Mit diesen neuesten allgemein verfügbaren Ankündigungen können Data Scientists und ML Engineers die Produktionsabläufe in Snowflake ML zuverlässig skalieren.
Die folgenden Ressourcen sind die einfachste Methode, um mit diesen neuen Funktionen zu beginnen:
Entwicklung: Probieren Sie diesen Quickstart zur Einführung zu Container Runtime aus, die Sie durch die Erfahrung führt, ein Notebook zu erstellen und ein einfaches ML-Modell zu entwickeln, und begleiten Sie dieses Anfänger-Video.
Inferenz: Erste Schritte mit diesem Beispiel für Einbettungsgenerierung mit einer zugehörigen Videoübersicht.
Monitoring: Folgen Sie diesem Quickstart zu den ersten Schritten mit ML Observability und sehen Sie sich hier eine fachkundige Demo an.
Weitere fortgeschrittene Anwendungsfälle finden Sie in den folgenden Lösungen:
Autor:innen



