The Apache Iceberg Avalanche: How the Open Table Format Changes the Face of Data Lakes

Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew. The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems. Data lake systems moved to more open formats but lacked the functional benefits that warehouses provide, such as ACID-compliant transactions, comprehensive governance and more. Ultimately, users found themselves stuck between two options: either a fully integrated platform with only proprietary solutions available or a resource-intensive, build-it-yourself, vendor-neutral data lake in a constant state of migration, in hopes of finally capturing promised value.
Now you don’t have to choose. With the advent and wide adoption of Apache Iceberg™, the open data lakehouse has emerged, combining the best of data warehouses and data lakes by decoupling open storage and compute to equip data teams with the flexibility and control of open architectures and the high performance of data warehouses. This is why Snowflake is fully embracing this open table format. Customers can now gain the benefits of storing data in a fully open, interoperable format while still harnessing the power of Snowflake's easy, connected and trusted platform. As a result, organizations can accelerate their open lakehouse strategies and deliver advanced analytics and AI faster.
What is Iceberg?
At the core of this open data lakehouse revolution is Iceberg, an open source table format for large analytic workloads. Iceberg isn’t a compute engine or even a database. It is a description of how a set of files can behave like a database table. Because the description is open and engine-independent, an Iceberg table is intrinsically vendor neutral. This combination of function and vendor-neutrality is ushering in the next stage of architecture evolution: the open lakehouse, where compute, format and storage are all decoupled from one another.
Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a user’s object storage. An external catalog tracks the latest table metadata and helps ensure consistency across multiple readers and writers.
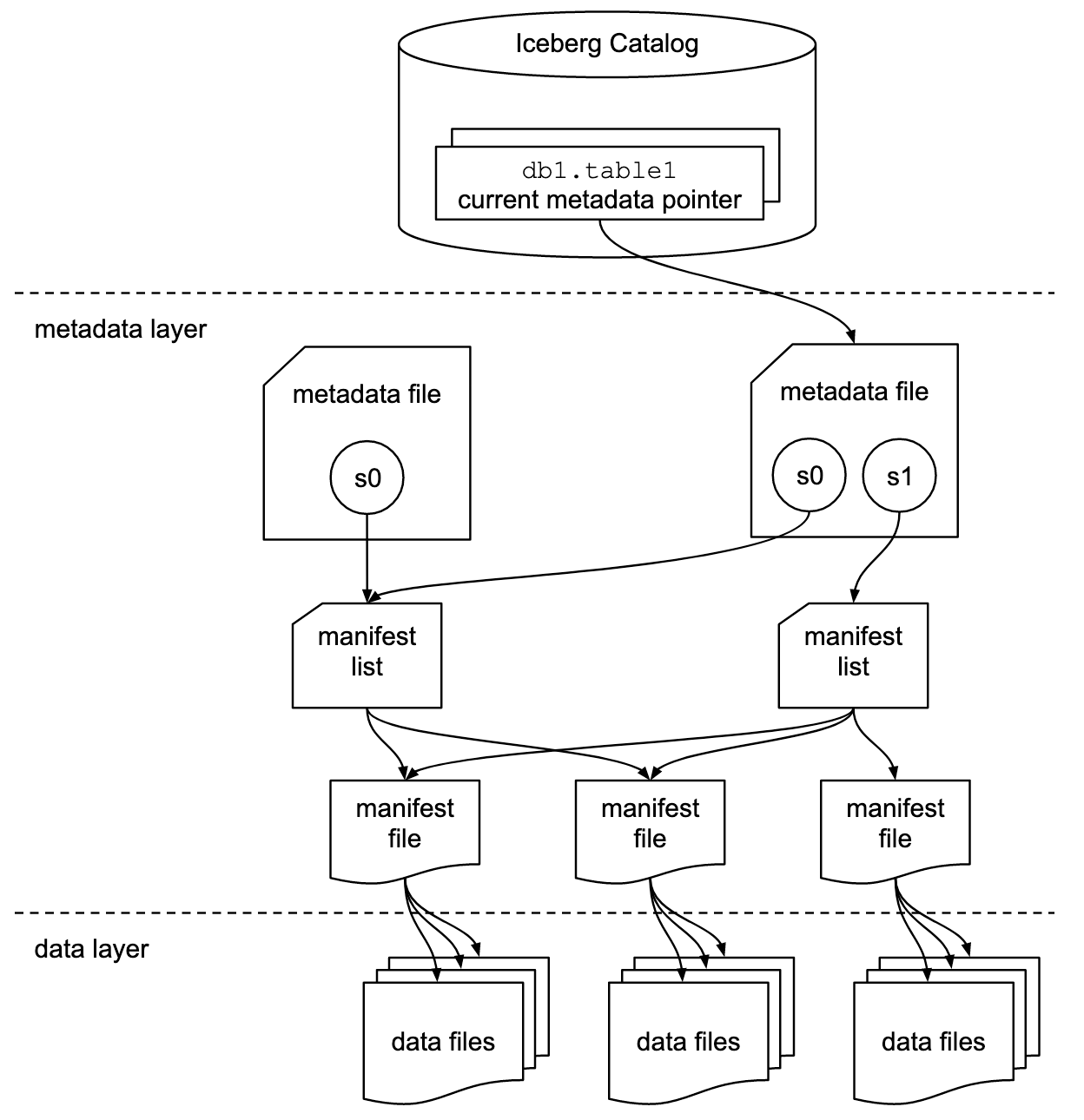
Put simply: Iceberg is metadata. Data files are tracked individually, rather than at the directory level, by manifest files, manifest lists and metadata files. This well-coordinated metadata layer means that Iceberg doesn’t fall victim to some of the more pernicious issues that other common table formats (e.g., Apache Hive™) encounter due to their strict reliance on a physical directory structure.
Why should you care about Iceberg?
Without adopting Iceberg tables, data teams are forced to spend significant time and resources managing migrations and governance before being able to capture the opportunities new technologies and solutions offer. Iceberg does away with this trade-off. By offering a fully interoperable storage format that allows data engineers to own and control their storage layer, Iceberg provides the flexibility to leverage any compatible modern data platform or compute engine. This means data teams can go from idea to impact in record time — without compromise — and deliver impact at the speed today’s businesses demand.
Here’s how data teams can benefit from grounding their open lakehouse architectures on Iceberg tables:
Higher developer productivity: Iceberg lets developers and data engineers work as if they are using a standard relational database such as Postgres but can scale up to petabytes of data.
Ability to write once, read everywhere: Iceberg is compatible with all of the latest analytics tools without migration. Switch engines or use multiple engines at the same time without penalty.
Faster compute: Iceberg's metadata layer is optimized for cloud storage, allowing for advance file and partition pruning with minimal IO overhead.
Because it is an open source standard, available for any tool or engine to support and take advantage of, Iceberg can bring these incredible gains to any organization. Ultimately, this openness is a win for you.
Being more open-minded
Snowflake has always put its users first. As technology continues to evolve, Snowflake continues to prioritize its customers by supporting open source initiatives. The benefits are clear: When users have choice, they win. This commitment to open source is underscored by Snowflake’s contributions to Iceberg to enable efficient, governed data lake management with schema evolution, partitioning and transaction management.
While Iceberg specifies how catalogs should behave, the Iceberg community has very intentionally stayed away from providing one. Given that the catalog manages the table’s metadata and helps ensure consistency across multiple readers and writers, this absence of a standardized catalog created the risk of reintroducing the trade offs Iceberg was meant to resolve. Specifically, it would again force organizations to decide between two options: either implement, manage and maintain a catalog themselves or leverage a vendor solution with the potential to get locked-in, again. Seeing this gap, Snowflake doubled down on its commitment to open standards and community-driven development by building and then open sourcing an Iceberg catalog and contributing it to the Apache Software Foundation, now known as Apache Polaris (incubating), in July 2024.
Polaris is a fully featured open source Iceberg catalog. It’s vendor-neutral by design, and the Polaris’ governance structure and community-driven development ensures it remains so. Polaris’ implementation of Iceberg’s REST API helps ensure consistency across multiple readers and writers and provides a means for atomically updating tables from one state to the next.
Not stopping there, Polaris also provides a centralized means of securing an organization’s data. Initially created as an interoperable Iceberg catalog, the Polaris roadmap now includes support for a broader range of data formats and data object types to help ensure that users can catalog all of their data from one place.
Building an open data lakehouse
Snowflake’s goal is to help organizations establish and accelerate their open lakehouse ambitions so they can unlock more impact with less complexity.
Get started:
Begin activating data stored in a cloud storage provider, without lock-in, by creating Iceberg tables directly from existing Parquet files in Snowflake.
Apply comprehensive security and governance controls within the Snowflake platform via Horizon Catalog.
Manage secure multi-engine access with Snowflake’s Open Catalog, a fully managed service for Polaris that preserves the option to self-manage by maintaining role-based access controls (RBAC), namespaces and definitions intact, regardless of where the catalog is hosted — nearly eliminating migration complexity.
Additionally, Snowflake’s elastic, zero-ops data engine continues to evolve with capabilities purposefully designed to improve query performance and efficiency for Iceberg tables. Customers get benefits like improved pruning techniques, which reduce cloud storage requests and speed up query execution, and Adaptive Scan, which unlocks faster execution of scan-heavy queries. These capabilities are available out of the box, without the need to go through a new implementation, thereby unlocking improved performance while lowering operational overhead.
Check out how WHOOP is reimagining its data architecture with Snowflake and Iceberg, saving 20 hours’ worth of compute every day and improving data accessibility across the organization.
Learn more
Join Snowflake at Iceberg Summit, a two-day event taking place in San Francisco on April 8 and virtually April 9. We are excited to support the community as a headlining sponsor for the inaugural event.
Tune into our webinar Data Engineering Connect: Building Pipelines for Open Lakehouse on April 29, featuring two virtual demos and a hands-on lab.
Read “The Essential Guide to Modernizing Data Lakes for AI with Snowflake,” offering expert guidance for creating the foundation to unlock the full potential of data and AI.
Authors
