COMMUNITY CERTIFIED
Monitoring customer churn with ML Observability in Snowflake
name: app_environment
channels:
- snowflake
dependencies:
- matplotlib=*
- modin=0.28.1
- seaborn=*
- snowflake=*
git clone git@github.com:Snowflake-Labs/sfguide-data-engineering-pipelines-with-pandas-on-snowflake.git
{
"cells": [
{
"cell_type": "markdown",
"id": "1dde02fa-0044-4b20-b7bb-10f1a5b3fabb",
"metadata": {
"collapsed": false,
"name": "cell1"
},
"source": [
"### Data Engineering Pipelines with pandas on Snowflake\n",
"\n",
"This demo is using the [Snowflake Sample TPC-H dataset](https://docs.snowflake.com/en/user-guide/sample-data-tpch) that should be in a shared database named `SNOWFLAKE_SAMPLE_DATA`. You can run this notebook in a Snowflake Notebook. \n",
"\n",
"During this demo you will learn how to use [pandas on Snowflake](https://docs.snowflake.com/developer-guide/snowpark/python/snowpark-pandas) to:\n",
"* Create datframe from a Snowflake table\n",
"* Aggregate and transform data to create new features\n",
"* Save the result into a Snowflake table\n",
"* Create a serverless task to schedule the feature engineering\n",
"\n",
"pandas on Snowflake is delivered through the Snowpark pandas API as part of the Snowpark Python library (preinstalled with Snowflake Notebooks), which enables scalable data processing of Python code within the Snowflake platform. \n",
"\n",
"Start by adding neccessary libraries using the `Packages` dropdown, the additional libraries needed for this notebook is: \n",
"* `modin` (select version 0.28.1)\n",
"* `snowflake`\n",
"* `matplotlib`\n",
"* `seaborn`"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4039104e-54fc-411e-972e-0f5a2d884595",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell2"
},
"outputs": [],
"source": [
"import streamlit as st\n",
"import matplotlib.pyplot as plt\n",
"import seaborn as sns"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d66adbc4-2b92-4d7d-86a5-217ee78e061f",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell3"
},
"outputs": [],
"source": [
"# Snowpark Pandas API\n",
"import modin.pandas as spd\n",
"# Import the Snowpark pandas plugin for modin\n",
"import snowflake.snowpark.modin.plugin\n",
"\n",
"from snowflake.snowpark.context import get_active_session\n",
"# Create a snowpark session\n",
"session = get_active_session()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "811abc04-f6b8-4ec4-8ad4-34af28ff8c31",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell4"
},
"outputs": [],
"source": [
"# Name of the sample database and the schema to be used\n",
"SOURCE_DATA_PATH = \"SNOWFLAKE_SAMPLE_DATA.TPCH_SF1\"\n",
"SAVE_DATA_PATH = \"SNOW_PANDAS_DE_QS.DATA\"\n",
"# Make sure we use the created database and schema for temp tables etc\n",
"session.use_schema(SAVE_DATA_PATH)"
]
},
{
"cell_type": "markdown",
"id": "0721a789-63a3-4c90-b763-50b8a1e69c92",
"metadata": {
"collapsed": false,
"name": "cell5"
},
"source": [
"We will start by creating a number of features based on the customer orders using the line items.\n",
"\n",
"Start with the `LINEITEM` table to create these features so we will start by creating a Snowpark Pandas Datframe aginst it, select the columns we are interested in and then show info about the dataframe, the shape and the first rows."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2a091f1b-505f-4b61-9088-e7fd08e16f83",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell6"
},
"outputs": [],
"source": [
"lineitem_keep_cols = ['L_ORDERKEY', 'L_LINENUMBER', 'L_PARTKEY', 'L_RETURNFLAG', 'L_QUANTITY', 'L_DISCOUNT', 'L_EXTENDEDPRICE']\n",
"lineitem_df = spd.read_snowflake(f\"{SOURCE_DATA_PATH}.LINEITEM\")[lineitem_keep_cols]"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "f360d4de-21f4-4723-9778-ceb8683c81c8",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell7"
},
"outputs": [],
"source": [
"st.dataframe(lineitem_df.head())"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "be5d37e2-e990-4e71-b762-41a64845955f",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell8"
},
"outputs": [],
"source": [
"# Get info about the dataframe\n",
"lineitem_df.info()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "618f45b8-a2a8-4d08-967e-945d2329335e",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell9"
},
"outputs": [],
"source": [
"print(f\"DataFrame shape: {lineitem_df.shape}\")"
]
},
{
"cell_type": "markdown",
"id": "e53fea0b-2f36-4662-a382-98938a74f2c2",
"metadata": {
"collapsed": false,
"name": "cell10"
},
"source": [
"## Data Cleaning - Filtering and Aggregation\n",
"\n",
"Taking a look at different values for `L_RETURNFLAG` and include only line items that was delivered (`N`) or returned (`R`)."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2f326c13-ed4c-4e6f-b40e-7e8338c270c4",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell11"
},
"outputs": [],
"source": [
"print(lineitem_df.L_RETURNFLAG.value_counts())"
]
},
{
"cell_type": "markdown",
"id": "122cb06a-3a08-4d32-8864-4c8ff8c046b4",
"metadata": {
"collapsed": false,
"name": "cell12"
},
"source": [
"Add a filter to the dataframe"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7f9c56b7-b2db-4591-97ce-451876e9b9a6",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell13"
},
"outputs": [],
"source": [
"print(f\"Before Filtering: {len(lineitem_df)} rows\")\n",
"spd_lineitem = lineitem_df[lineitem_df['L_RETURNFLAG'] != 'A']\n",
"print(f\"After Filtering: {len(spd_lineitem)} rows\")\n",
"st.dataframe(spd_lineitem.head())"
]
},
{
"cell_type": "markdown",
"id": "1f802173-162f-4dff-8567-ade65b9f57f1",
"metadata": {
"collapsed": false,
"name": "cell14"
},
"source": [
"To track the actual discount a customer gets per order, we need to calculate that in a new column by taking the product of the amount of discount (`L_DISCOUNT`), numbers sold (`L_QUANTITY`), and the price of item (`L_EXTENDEDPRICE`)."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "58f45f3d-3633-424e-b777-467a2ba0b22d",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell15"
},
"outputs": [],
"source": [
"spd_lineitem['DISCOUNT_AMOUNT'] = spd_lineitem['L_DISCOUNT'] * spd_lineitem['L_QUANTITY'] * spd_lineitem['L_EXTENDEDPRICE']\n",
"st.dataframe(spd_lineitem.head())"
]
},
{
"cell_type": "markdown",
"id": "6ec9d862-e957-42b9-9d86-03f2ad3501f7",
"metadata": {
"collapsed": false,
"name": "cell16"
},
"source": [
"Now we want to compute the aggregate of items and discount amount, grouped by order key and return flag.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "578cbdf7-a655-416b-87da-417f7edd35bb",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell17"
},
"outputs": [],
"source": [
"# Aggregations we want to do\n",
"column_agg = {\n",
" 'L_QUANTITY':['sum'], # Total Items Ordered \n",
" 'DISCOUNT_AMOUNT': ['sum'] # Total Discount Amount\n",
" }\n",
"\n",
"# Apply the aggregation\n",
"spd_lineitem_agg = spd_lineitem.groupby(by=['L_ORDERKEY', 'L_RETURNFLAG'], as_index=False).agg(column_agg)\n",
"\n",
"# Rename the columns\n",
"spd_lineitem_agg.columns = ['L_ORDERKEY', 'L_RETURNFLAG', 'NBR_OF_ITEMS', 'TOT_DISCOUNT_AMOUNT']\n",
"st.dataframe(spd_lineitem_agg.head())"
]
},
{
"cell_type": "markdown",
"id": "00dd1299-9bb2-4aba-9f37-b04ca3639892",
"metadata": {
"collapsed": false,
"name": "cell18"
},
"source": [
"## Data Transformation - Pivot and reshape\n",
"\n",
"We want to separate the `NBR_OF_ITEMS` and `TOT_DISCOUNT_AMOUNT` by `L_RETURNFLAG` so we have one column for each uinique `L_RETURNFLAG` value. \n",
"Using the **pivot_table** method will give us one column for each unique value in `RETURN_FLAG`"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7f586e8a-017b-4672-80a1-bcc9430a87c3",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell19"
},
"outputs": [],
"source": [
"# This will make L_ORDERKEY the index\n",
"spd_lineitem_agg_pivot_df = spd_lineitem_agg.pivot_table(\n",
" values=['NBR_OF_ITEMS', 'TOT_DISCOUNT_AMOUNT'], \n",
" index=['L_ORDERKEY'],\n",
" columns=['L_RETURNFLAG'], \n",
" aggfunc=\"sum\")"
]
},
{
"cell_type": "markdown",
"id": "38dd144f-b18b-4673-b8c0-7db6d237ae59",
"metadata": {
"collapsed": false,
"name": "cell20"
},
"source": [
"The **pivot_table** method returns subcolumns and by renaming the columns we will get rid of those, and have one unique columns for each value."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6166f8b0-fc8c-451e-9780-3e1f634ccbdd",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell21"
},
"outputs": [],
"source": [
"spd_lineitem_agg_pivot_df.columns = ['NBR_OF_ITEMS_N', 'NBR_OF_ITEMS_R','TOT_DISCOUNT_AMOUNT_N','TOT_DISCOUNT_AMOUNT_R']\n",
"# Move L_ORDERKEY back to column\n",
"spd_lineitem_agg_pivot = spd_lineitem_agg_pivot_df.reset_index(names=['L_ORDERKEY'])\n",
"st.dataframe(spd_lineitem_agg_pivot.head(10))"
]
},
{
"cell_type": "markdown",
"id": "1657bbc7-caf2-461c-9302-6f8d2187e0af",
"metadata": {
"collapsed": false,
"name": "cell22"
},
"source": [
"## Combine lineitem with orders information\n",
"\n",
"Load `ORDERS` table and join with dataframe with transformed lineitem information."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c910ac10-38b3-4aa4-a7d2-6321243a4a60",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell23"
},
"outputs": [],
"source": [
"spd_order = spd.read_snowflake(f\"{SOURCE_DATA_PATH}.ORDERS\")\n",
"# Drop unused columns \n",
"spd_order = spd_order.drop(['O_ORDERPRIORITY', 'O_CLERK', 'O_SHIPPRIORITY', 'O_COMMENT'], axis=1)\n",
"# Use streamlit to display the dataframe\n",
"st.dataframe(spd_order.head())"
]
},
{
"cell_type": "markdown",
"id": "97d52cd4-a71b-4c72-9137-accdf54b571b",
"metadata": {
"collapsed": false,
"name": "cell24"
},
"source": [
"Use **merge** to join the two dataframes"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6aee6f94-f33b-4492-9f89-2808c05f07d4",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell25"
},
"outputs": [],
"source": [
"# Join dataframes\n",
"spd_order_items = spd_lineitem_agg_pivot.merge(spd_order,\n",
" left_on='L_ORDERKEY', \n",
" right_on='O_ORDERKEY', \n",
" how='left')"
]
},
{
"cell_type": "markdown",
"id": "3adc0331-1879-452f-9cc6-dd69f6824974",
"metadata": {
"collapsed": false,
"name": "cell26"
},
"source": [
"Drop the `L_ORDERKEY`column, it has the same values as `O_ORDERKEY`"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8504a44d-d687-4c8d-af78-4b802901a168",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell27"
},
"outputs": [],
"source": [
"spd_order_items.drop('L_ORDERKEY', axis=1, inplace=True)\n",
"st.write(f\"DataFrame shape: {spd_order_items.shape}\")\n",
"st.dataframe(spd_order_items.head())"
]
},
{
"cell_type": "markdown",
"id": "a8b050f9-77a9-460a-853b-888963e6a214",
"metadata": {
"collapsed": false,
"name": "cell28"
},
"source": [
"More aggregations grouped by customer (`O_CUSTKEY`)\n",
"* Total items delivered by customer\n",
"* Average items delivered by customer\n",
"* Total items returned by customer\n",
"* Average items returned by customer"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "36e32341-cc93-4b5d-a5f1-15a15d8ddf69",
"metadata": {
"codeCollapsed": false,
"collapsed": false,
"language": "python",
"name": "cell29"
},
"outputs": [],
"source": [
"# Aggregations we want to do\n",
"column_agg = {\n",
" 'O_ORDERKEY':['count'], \n",
" 'O_TOTALPRICE': ['sum' ,'mean', 'median'],\n",
" 'NBR_OF_ITEMS_N': ['sum' ,'mean', 'median'],\n",
" 'NBR_OF_ITEMS_R': ['sum' ,'mean', 'median'],\n",
" 'TOT_DISCOUNT_AMOUNT_N': ['sum'],\n",
" 'TOT_DISCOUNT_AMOUNT_R': ['sum']\n",
" }\n",
"\n",
"# Apply the aggregation\n",
"spd_order_profile = spd_order_items.groupby(by='O_CUSTKEY', as_index=False).agg(column_agg)\n",
"\n",
"# Rename the columns\n",
"spd_order_profile.columns = ['O_CUSTKEY', 'NUMBER_OF_ORDERS', 'TOT_ORDER_AMOUNT', 'AVG_ORDER_AMOUNT', 'MEDIAN_ORDER_AMOUNT', \n",
" 'TOT_ITEMS_DELIVERED', 'AVG_ITEMS_DELIVERED', 'MEDIAN_ITEMS_DELIVERED', \n",
" 'TOT_ITEMS_RETURNED', 'AVG_ITEMS_RETURNED', 'MEDIAN_ITEMS_RETURNED',\n",
" 'TOT_DISCOUNT_AMOUNT_N', 'TOT_DISCOUNT_AMOUNT_R']\n",
"st.dataframe(spd_order_profile.head())"
]
},
{
"cell_type": "markdown",
"id": "daf0e441-43d1-4729-bc20-aea8f123befa",
"metadata": {
"collapsed": false,
"name": "cell30"
},
"source": [
"Calculate the total and average discount"
]
}Overview
Snowflake ML provides a unified platform for end-to-end ML development and operations on governed data. And MLOps streamlines model deployment, maintenance, and monitoring, addressing challenges like:
Input drift and outdated training assumptions
Issues in data pipelines and hardware/software environments
Trend changes leading to performance degradation
This solution architecture shows how to carry continuous monitoring in ML Models in Snowflake and reduce customer churn for a financial company. You will learn to :
Build a comprehensive and scalable production-ready MLOps pipeline that manages the entire ML workflow in Snowflake ML.
Implement model performance tracking across multiple dimensions, such as performance, drift, and volume via the Snowflake Model Registry.
Carry monitoring of customer churn classification model
Solution Architecture: ML Observability in Snowflake
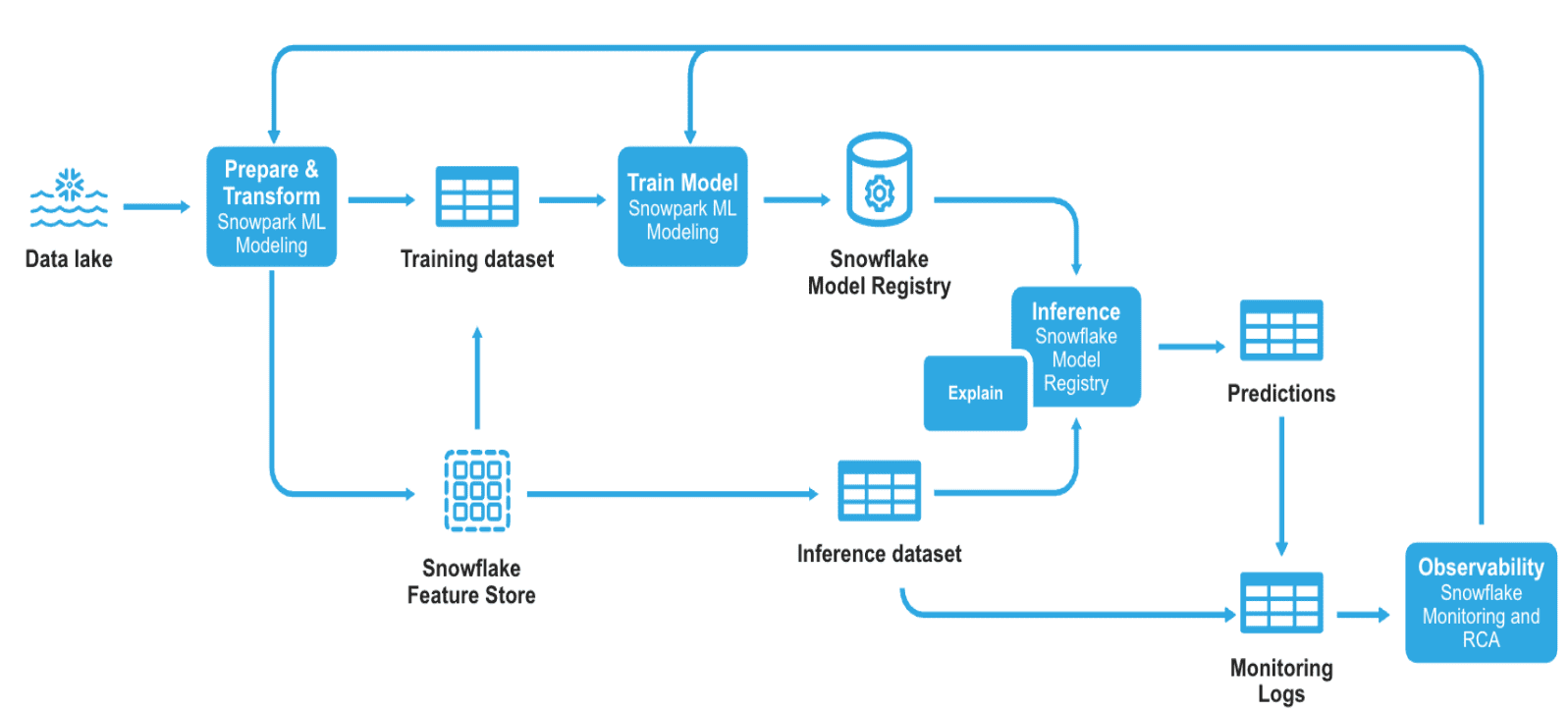
About the Architecture
It outlines the end-to-end workflow, from data preparation to monitoring model performance. Here's a breakdown:
Data Ingestion
Raw data is sourced from the Data Lake.
Data Preparation & Feature Engineering
Prepare & Transform (Snowpark ML Preprocessing API) processes the raw data.
Model Training & Registration
The training dataset is used to train the model using Snowpark ML Modeling.
The trained model is registered in the Snowflake Model Registry.
Inference & Predictions
The model stored in the Snowflake Model Registry is used for inference (predictions).
Monitoring & Observability
Drift, Performance and Statistical metrics are logged for continuous monitoring.
ML Observability ensures tracking of:
Precision
F1 Score
Classification accuracy
Recall Ratio
This solution was sourced by a member of the Snowflake Community. It is not maintained on an ongoing basis and may be out of date with current Snowflake instances.
Solution not working as expected? Contact our team for assistance.