Agentic Semantic Model Improvement: Elevating Text-to-SQL Performance

Cortex Analyst helps businesses query their data using natural language by translating it into SQL. This works thanks to a semantic model that connects business terms to database schema. It guides LLMs to build more accurate SQL queries by including the right elements, such as joins and filters.
Crafting this semantic model is tough. It involves matching business logic with database structures, a process that even experts find time-consuming and prone to errors.
We've developed a new approach: an agentic system that uses LLMs to improve the provided semantic model. By combining this system with structured validation and schema-aware parsing, we observed a reduction in manual effort and a boost in SQL accuracy by 20% (on average) over LLMs alone.
Overview
Cortex Analyst is an agentic AI system that uses multiple internal LLM Agents to answer data questions reliably. At its core, it combines these LLMs with a detailed semantic model of data sources. This semantic model acts like a knowledge base, giving LLMs the context they need to understand user questions accurately — similar to how a human analyst would.
The semantic model captures important details, such as:
Descriptive names for database elements
Metrics/filters specific to the data and the business
Synonyms for fields and business terms
Relationships between tables
Custom instructions for specific queries
These elements help Cortex Analyst maintain precision and reliability.
For this version of the semantic model improvement system, we tested it using the BIRD-SQL data set. BIRD-SQL offers a comprehensive benchmark for text-to-SQL systems, typically used for fine-tuning models. We used its question-SQL pairs to refine our semantic-model-generation process.
Working with BIRD-SQL, though, presented some challenges:
The average human accuracy of 93% on BirdSQL underscores the inherent difficulty of this text-to-SQL task, confirming it's challenging even for humans fluent in SQL.
Its use of MySQL syntax required adapting examples to Snowflake SQL, but not all could run directly, so some were removed altogether.
We carefully filtered the data set and focused on four specific areas from the dev set:
Debit card specialization
California schools
Thrombosis prediction
Toxicology
Each area provided tables, external knowledge and sets of questions with evidence and expected SQL. We analyzed these using our Evaluation Agent.
While this article focuses on BIRD-SQL, our system is designed for real-world use. BIRD-SQL helps us refine the process, with the ultimate goal of unlocking Cortex Analyst's full potential for customers.
How we automated semantic model improvement with agents
Building a better semantic model
Creating a semantic model in Cortex Analyst isn't easy. It involves turning complex business logic into structured SQL. Our new Semantic Model Dev UI (currently in PuPr) helps by making it simpler to select tables and columns and auto-generate descriptions. But some parts still need manual work:
Setting up relationships
Defining metrics
Integrating with Cortex Search
Writing custom instructions
To make this easier, we've developed an agentic system. It automates key parts of the semantic model, reducing complexity. This lets creators focus on refining the model's overall structure.
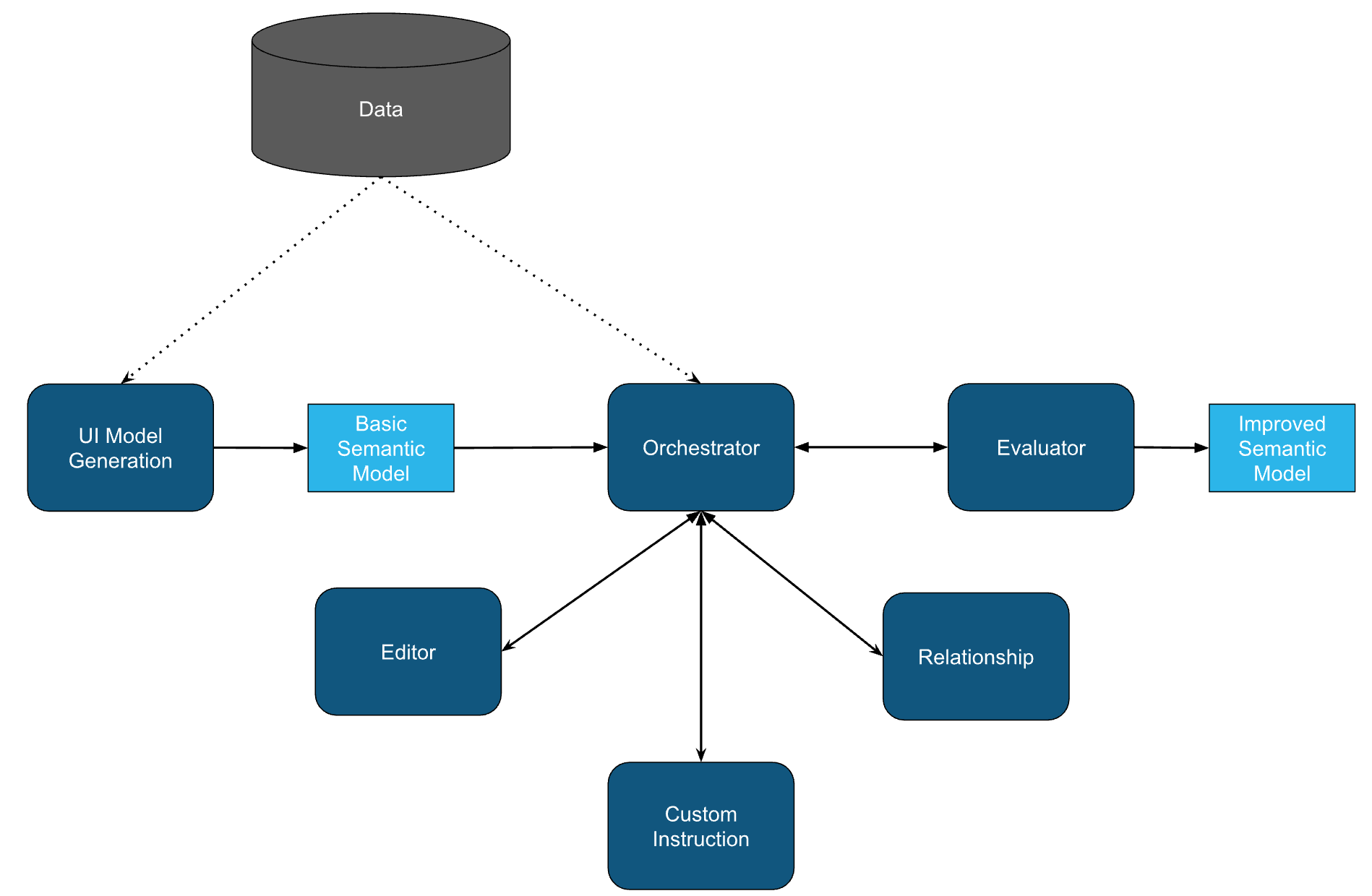
How our agents work together
We use several specialized agents to improve the semantic model:
Model Creation: We start by auto-generating basic models using the Snowsight tool. We use external knowledge and primary key info from the BIRD data sets. These models are a good start, but they need more detail.
Orchestrator: This agent manages all the others. It decides when and how to use each agent to refine the model step-by-step.
Relationships Agent: This agent looks at the correct SQL and primary keys to figure out how tables are connected. It can do this even without explicit database definitions.
Semantic Model Editor: This agent reviews the current model, correct SQL and generated SQL, and then evaluates the results. It suggests edits to align with business logic and fix errors. It also uses question evidence to improve column and metric descriptions.
Custom Instruction Editor: This agent writes special instructions for SQL generation that apply to the whole model. These instructions help bridge gaps between the model and desired output, addressing domain-specific needs.
Evaluator: Evaluating text-to-SQL systems is tricky. Simple comparisons often miss the mark. We use a two-step process:
First, we compare columns.
Second, if there are differences, we use an agent to compare data frames and check if both answers address the original question.
This is important because two results could be correct and similar even when the data returned is different. Consider the following example.
Question: What is the most expensive product?
Output1:
| Product | Price |
|---|---|
| Cars | 1000 |
| Books | 500 |
| Toys | 200 |
Output2:
| Most Expensive Product |
|---|
| Cars |
Baseline (Vanilla LLM): To measure improvement, we tested the same LLM agent with a prompt built from the data set's database structure and external knowledge. This gives us a clear comparison point.
Models Used
We utilized the Claude 3.5 Sonnet as the primary model for SQL generation in both the Snowflake Cortex Analyst and the Vanilla LLM approach. The LLM_JUDGE was Mistral Large 2, which had exhibited strong performance on various questions and answers in our prior investigations.
Results
| Data set name | # of questions | Vanilla Claude 3.5 Sonnet | Cortex Analyst (Claude 3.5 Sonnet) | Improvement |
|---|---|---|---|---|
| debit_card_specializing | 60 | 52% | 83% | 31% |
| california_schools | 80 | 63% | 80% | 17% |
| thrombosis_prediction | 111 | 45% | 70% | 25% |
| toxicology | 141 | 69% | 79% | 10% |
| Average | 57% | 78% | 21% |
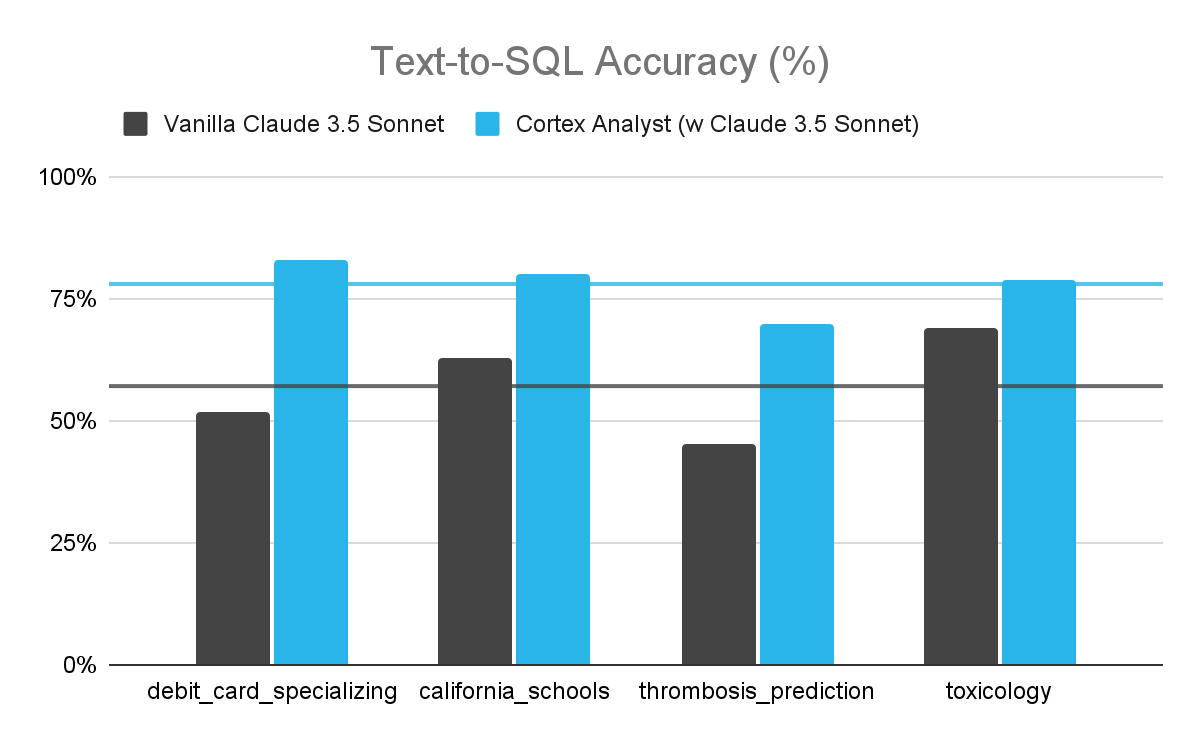
The results demonstrate that our automated system for semantic model improvement significantly improves text-to-SQL accuracy. This illustrates the effectiveness of our agent-driven approach in refining semantic models and enhancing query performance. We can see that the Cortex Analyst system significantly improved the results, as compared to the standard Claude 3.5 Sonnet. On average, across the four data sets, we observed an approximately 20% increase in accuracy over the version lacking a proper semantic model.
Examples
Example 1
Database: debit_card_specializing
Question: How many gas stations in the Czech Republic offer Premium gas?
Results: When providing this question and similar context to both Claude 3.5 Sonnet without using Cortex Analyst and to Cortex Analyst, we found Claude 3.5 Sonnet was incorrectly joining tables (despite this information being provided), and incorrectly identifying "premium gas" as a segment instead of a description, leading to an invalid SQL query.
Claude 3.5 Sonnet (Incorrect):
SELECT
COUNT(DISTINCT g.GasStationID) AS premium_stations
FROM
autosql_dataset_bird_v2.debit_card_specializing.GasStations g
JOIN
autosql_dataset_bird_v2.debit_card_specializing.Transactions_1K t ON g.GasStationID = t.GasStationID
JOIN
autosql_dataset_bird_v2.debit_card_specializing.Products p ON t.ProductID = p.ProductID
WHERE
g.Country = 'CZE'
AND p.Description LIKE '%Premium%';Cortex Analyst (Correct):
WITH __gasstations AS (
SELECT
country,
segment
FROM
autosql_dataset_bird_v2.debit_card_specializing.gasstations
)
SELECT
COUNT(*) AS premium_station_count
FROM
__gasstations AS g
WHERE
g.country = 'CZE'
AND g.segment = 'Premium';Example 2
Database: california_schools
Question: What is the phone number of the school that has the highest average score in Math?
Result: From our testing, Claude's query incorrectly returned all schools sharing the maximum math score, not a single highest, and includes extra columns; furthermore, due to potential NULL values, its subquery might fail, resulting in a no result.
BIRD-SQL (Correct):
SELECT
T1.Phone
FROM
autosql_dataset_bird_v2.california_schools.schools AS T1
INNER JOIN
autosql_dataset_bird_v2.california_schools.satscores AS T2 ON T1.CDSCode = T2.cds
ORDER BY
T2.AvgScrMath DESC NULLS LAST
LIMIT 1;Claude Raw SQL (Incorrect):
SELECT
s.PHONE,
sat.AVGSCRMATH,
s.SCHOOL
FROM
SCHOOLS s
JOIN
SATSCORES sat ON s.CDSCODE = sat.CDS
WHERE
sat.AVGSCRMATH = (
SELECT
MAX(AVGSCRMATH)
FROM
SATSCORES
)
AND s.PHONE IS NOT NULL;Cortex Analyst SQL (Correct):
WITH __schools AS (
SELECT
cdscode,
school,
phone
FROM
autosql_dataset_bird_v2.california_schools.schools
),
__satscores AS (
SELECT
cds,
avgscrmath
FROM
autosql_dataset_bird_v2.california_schools.satscores
),
ranked_schools AS (
SELECT
s.school,
s.phone,
sat.avgscrmath,
RANK() OVER (ORDER BY sat.avgscrmath DESC NULLS LAST) AS rnk
FROM
__schools AS s
INNER JOIN
__satscores AS sat ON s.cdscode = sat.cds
)
SELECT
school,
phone,
avgscrmath
FROM
ranked_schools
WHERE
rnk = 1; -- Generated by Cortex AnalystThe number of mismatches could be even lower, as our analysis did not exclude any "incorrect" SQL from BIRD. This means that every mismatch was counted as a point against our test-to-SQL system.
For instance, we found some issues with the BIRD data set, which can be illustrated with the following example from the debit card data set.
Question: Which country has more "value for money" gas stations? Please provide the total number of "value for money" gas stations in each country.
Results: The BIRD-SQL query is incorrect because its subquery provides a global count, not a count per country. In contrast, Cortex Analyst correctly groups and counts gas stations by country before selecting the top result.
BIRD-SQL (Incorrect):
SELECT
Country,
(
SELECT
COUNT(GasStationID)
FROM
autosql_dataset_bird_v2.debit_card_specializing.gasstations
WHERE
Segment = 'Value for money'
)
FROM
autosql_dataset_bird_v2.debit_card_specializing.gasstations
WHERE
Segment = 'Value for money'
GROUP BY
Country
ORDER BY
COUNT(GasStationID) DESC NULLS LAST
LIMIT 1;Cortex Analyst (Correct):
WITH __gasstations AS (
SELECT
country,
segment,
gasstationid
FROM
autosql_dataset_bird_v2.debit_card_specializing.gasstations
)
SELECT
g.country,
COUNT(g.gasstationid) AS value_for_money_stations
FROM
__gasstations AS g
WHERE
g.segment = 'Value for money'
GROUP BY
g.country
ORDER BY
value_for_money_stations DESC NULLS LAST
-- Generated by Cortex Analyst
;Conclusion
Our evaluations on the BIRD data sets clearly demonstrate the transformative power of well-crafted semantic models for text-to-SQL systems. By automating the refinement of these models, our agentic system can significantly enhance query accuracy and reliability. However, this is just a stepping stone. We are actively developing strategies to further streamline and automate the creation of robust semantic models, making their benefits accessible to a broader audience. Future work will detail our efforts to handle increasingly complex data relationships and ensure data integrity, solidifying the role of automated semantic model creation as a cornerstone of efficient data interaction
Contributors
Team working on the effort: Kelvin So Joe Liang
Special thanks to Kyle Schmaus, Aiwen Xu, Abhinav Vadrevu and all other team members.
Authors
