How Snowflake Optimizes Apache Iceberg Queries with Adaptive Execution

In this blog post, we dive into Adaptive Scan, a powerful new performance feature that dynamically adjusts I/O parallelism and memory allocation during table scans by leveraging real-time system metrics to optimize resource utilization.
Our observed results speak for themselves: up to 70% faster execution for scan-heavy queries accessing small regions from micro-partitions in production and a 30% improvement in memory efficiency for high-concurrency scenarios (based on internal review of 60 accounts). These enhancements are particularly impactful for Snowflake workloads using Apache Iceberg, which are increasingly adopted for managing large-scale analytical data due to their flexibility and performance benefits. Iceberg query performance depends heavily on the execution engine; Snowflake’s adaptive compute engine excels in delivering intelligent optimizations that enhance efficiency, scalability and cost effectiveness.
Adaptive Scan
Snowflake's multi-cluster shared data architecture improves query execution by caching frequently accessed data in virtual warehouse nodes' local SSDs, reducing network traffic to remote storage. Snowflake's execution engine utilizes an asynchronous I/O architecture, and this allows the warehouse nodes to overlap I/O operations with CPU processing. Since different workloads have varying characteristics and bottlenecks, we designed Adaptive Scan to adaptively scale I/O throughput in accordance with data processing throughput while keeping memory under control.
This dynamic adjustment considers factors such as request size, processing complexity and storage latency. For small request sizes, Adaptive Scan increases background threads to optimize resource utilization, while avoiding unnecessary I/O for CPU-bound queries. It adapts caching behavior, manages concurrent queries to prevent bottlenecks and leverages network bandwidth when beneficial. Importantly, it prevents performance regression by scaling down threads only when ineffective, making it broadly applicable across different table types and cloud providers.
To further enhance the adaptive capability in the scanner and optimize memory usage during query processing, we've implemented a "Memory Barrier" mechanism that particularly helps when dealing with large files, as they can lead to significant memory allocation and potential retries due to memory pressure reducing overall efficiency.
The core idea of Memory Barrier is to act as a gatekeeper, controlling whether a scanner thread can allocate memory. The Memory Barrier does this by actively maintaining the state of active scanner threads and their memory consumption. A central synchronization mechanism coordinates memory allocation requests from different scanners. If enough memory is available, the scanner proceeds. Otherwise, it pauses temporarily until memory becomes available. The Memory Barrier ensures a minimum level of concurrency to maintain query progress even under memory pressure, thereby ensuring progress.
Results
We conducted various experiments to evaluate how effectively adaptiveness improves performance across different scenarios. We designed a simple scan-bound query against the catalog_sales table from the TPC-DS 10-TB data set, where execution time is primarily determined by the I/O rate.
select hash_agg(cs_wholesale_cost)
from catalog_sales
where true
and cs_wholesale_cost between 40 and 42
;Note: We use hash_agg() to eliminate result writing overhead.
We tested this query under three different scenarios:
Externally managed Iceberg: Parquet files originated from Spark with large partition sizes.
Snowflake-managed Iceberg: Large partitions (file size up to 128 MB).
Snowflake-managed Iceberg: Small partitions (file size up to 16 MB).
To assess performance, we executed each query consecutively to observe its impact on both cold and warm runs. Improvements are showcased as percentage improvement over 100 (baseline run with no optimization) in the charts below.
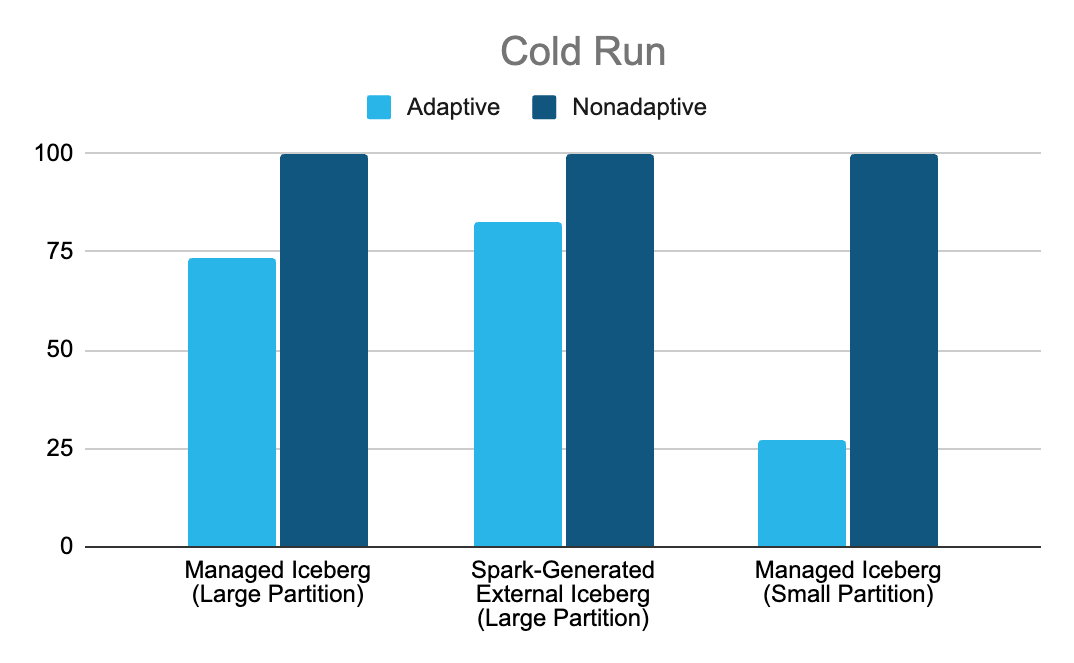
It is evident that Adaptive Scan significantly improves performance across all variations. The most significant performance boost (up to 70%) we observed occurred with small partition sizes, where request sizes are the smallest. With small partition sizes, the number of partitions increases for the same data, amplifying the cold cache impact on request latency. Adaptive Scan mitigates this by scaling up background I/O threads to hide latency and maintain throughput.
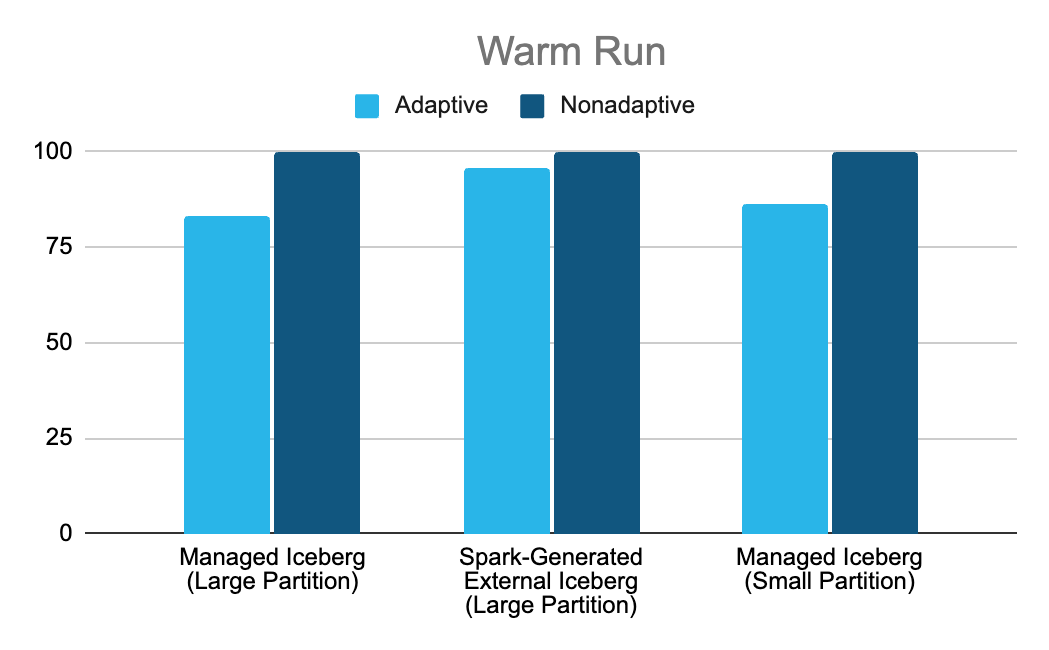
Similarly, in the warm run, we observed performance improvements across the board, with gains of up to 20%. In this scenario, data is loaded from both the cache and remote storage, effectively utilizing both disk and network bandwidth to achieve high-throughput data loading.
TPC-DS benchmark
Moving beyond atomic queries, we evaluated the impact of this feature using the industry-standard TPC-DS benchmark on Snowflake-managed Iceberg tables. In the chart below, each blue bar represents the ratio of execution time with Adaptive Scan enabled versus disabled. A ratio of less than 1 indicates improved query performance with Adaptive Scan enabled.
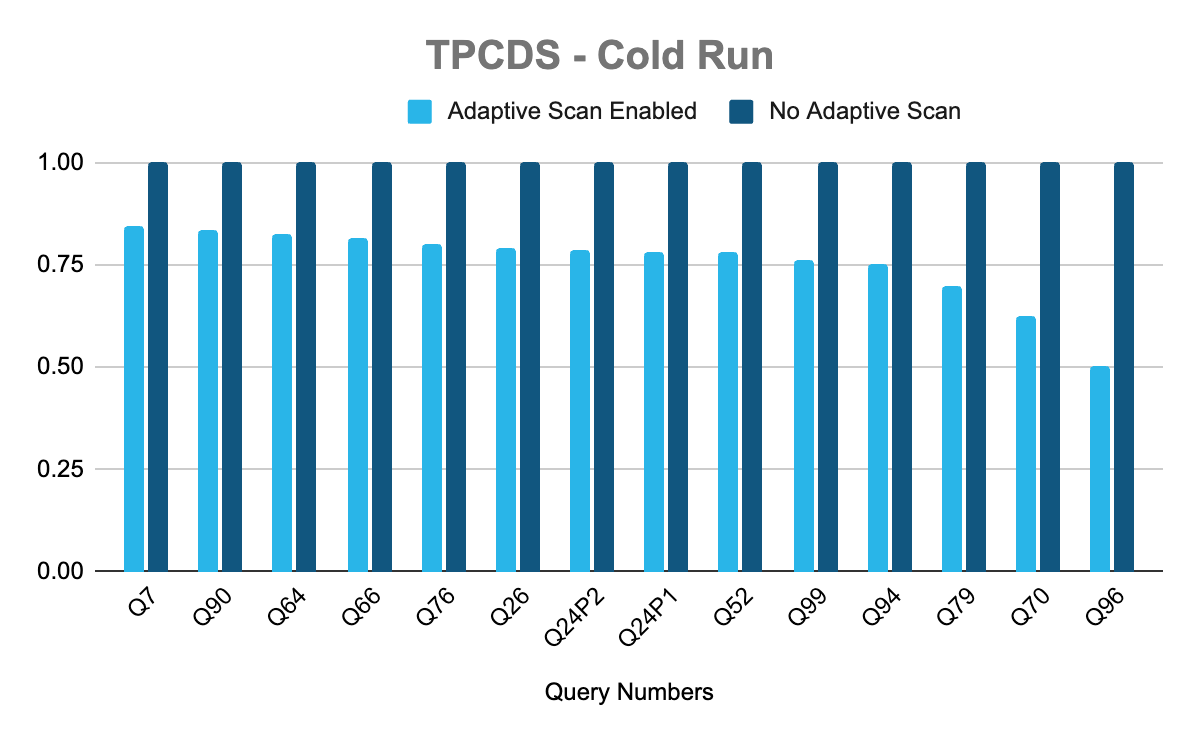
In the cold run, 14 queries (out of 103 total) demonstrated performance improvements of over 10%. The most significant beneficiary was Q96, which improved by 50%. Since Q96 scans large volumes of data, it was able to fully leverage burst network throughput, resulting in substantial performance gains.
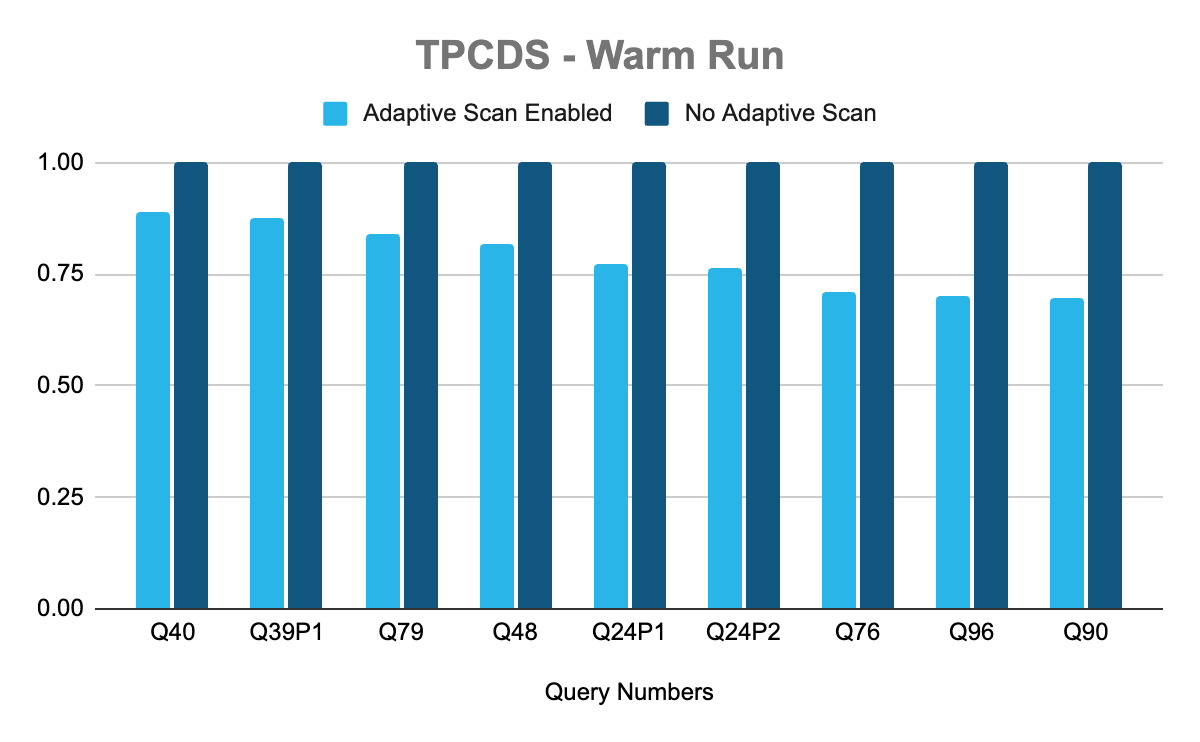
In the warm run, seven queries (out of 103 total) exhibited performance improvements of over 10%. A common pattern among these queries was that scanning speed was the primary bottleneck in their execution times. Conversely, queries that were already CPU-bound showed no performance difference, as their execution was constrained by data processing speed rather than data loading speed.
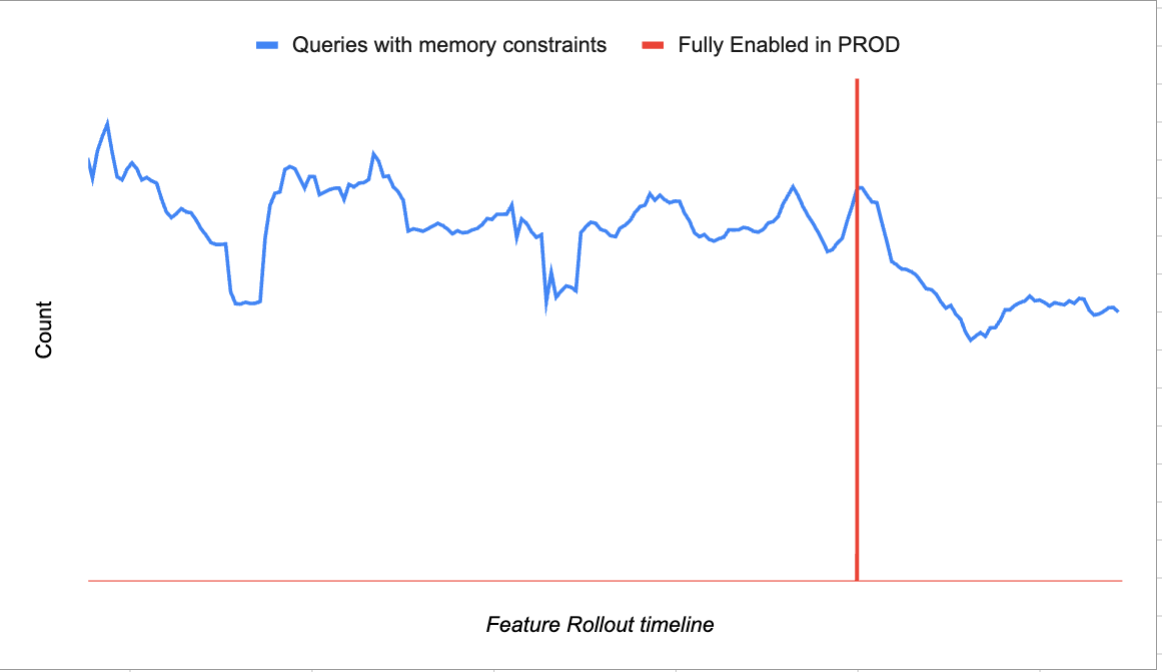
For memory adaptiveness, with the feature enabled we saw a 30% improvement in memory efficiency (based on results from 60 accounts) on workloads that witnessed heavy concurrency, and this improvement will be showcased more while scanning large files (common with Iceberg workloads). This resulted in not only faster workloads but savings for the customer.
Both features are fully enabled in production and we are witnessing similar improvements in a number of real-world customer scenarios.
Conclusion
The need for adaptivity in query execution is evident across various workloads and scenarios. Fixed configurations fail to account for variations in data characteristics, sizes and system constraints, leading to inefficiencies. With these optimizations, Snowflake is best positioned to support the different flavors of customer workloads influenced by open table formats such as Iceberg.
Authors

