Snowflake’s Data Architecture: Enabling AI Apps, Next-Gen Lakehouse Analytics And More

In a previous blog post, we described the challenges of building the Snowflake AI Data Cloud and the key design elements in Snowflake’s architecture that address them. In this post, we take a closer look at how Snowflake builds a cloud for all data: structured, semistructured and unstructured data; domain- and application-specific data; and data used in different types of workloads, such as AI applications, analytics and business intelligence, transactional processing, streaming and data engineering. We also highlight the key design choices that enable Snowflake to support open data lake and other enterprise data architectures through a unified platform and enable Snowflake customers to utilize them in the same product.
The Snowflake data and metadata model, data storage, as well as data governance are the building blocks in the Snowflake architecture that enable this. On a high level, Snowflake’s data architecture solves the following problems:
Representing and processing different forms of data efficiently and in a semantically consistent manner
Processing data with different types of encodings stored in open data lakes or native formats
Encoding and storing such data while leveraging underlying storage infrastructure primitives
Uniformly governing and managing data
This post takes a closer look at how these problems are solved by Snowflake.
The architecture
Snowflake uses different data layouts to optimize storage and precessing of different data types and workloads. Columnar data layout in Iceberg and native Snowflake tables are used to power analytical workloads, while record-based in-memory and on-disk storage layouts are employed to support hybrid transactional and analytical data.
Snowflake leverages two data formats to store columnar data: the Snowflake columnar data format and Apache Parquet. Both formats are designed based on the PAX model: Data for each column is encoded and compressed in blocks and stored contiguously in the files. Auxiliary metadata, such as minimum and maximum values in the file metadata, help the reader to quickly find the right blocks of data that match the predicates. Hybrid transactional and analytical data are encoded and stored in a combination of row-oriented and columnar layouts. Finally, unstructured, multimodal data is stored in any arbitrary layout or encoding appropriate for that content type (e.g., PDF documents, JPEG images, various audio formats).
A key design element of the Snowflake architecture is the decoupling of the data layout from the table metadata and format, as well as the in-memory representation of the data used in the data flow engine. This decoupling is critical in enabling the Snowflake query engine to work with multiple data encodings, such as Parquet and Snowflake columnar format. This ability enables Snowflake to interoperate with various data lakes, and data management and processing tools outside of Snowflake, while supporting Hybrid Tables and unstructured data in non-columnar formats.
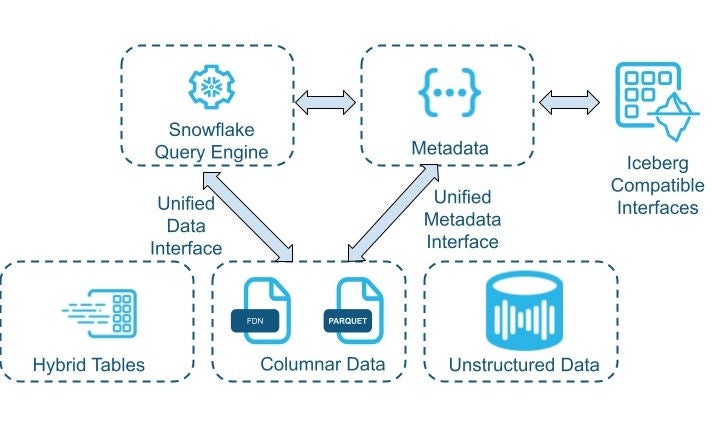
Data representation and encoding
The AI Data Cloud should support intelligent and efficient management of a diverse set of complex data, including unstructured, multimodal and machine-generated data, as they become more prevalent in data processing. To that end, Snowflake’s data model provides key abstractions combined with efficient physical implementations. This model is designed to work with different encodings on the data without any changes to the query engine or metadata system.
Unstructured data
With the proliferation of large language models (LLMs), analytics on unstructured data has become increasingly important and more broadly available. Snowflake Cortex AI enables AI-powered analytics as well as building AI applications on unstructured data.
Snowflake supports the management, storage and processing of unstructured data through the same overall governance and processing framework as structured data.
Cortex Search enables LLM-powered retrieval-augmented generation (RAG) and enterprise search use cases on top of unstructured data. The hybrid search works seamlessly on Snowflake native storage through uniform support of the storage and the query engine to represent and process unstructured data representation as well as embeddings. Document AI and Cortex LLM functions further expand the analytics to unstructured data by intelligently extracting structured information that is represented and processed through the Snowflake data flow engine, which can subsequently be combined with other structured and semistructured business data.
In addition to Cortex AI, Snowflake’s support for storing and processing unstructured data enables a wide range of data engineering tasks. Unstructured data is represented through directory tables and scoped URLs and can be processed and transformed through features, such as external functions, user-defined functions and stored procedures, as well as Snowpark. They all operate within the same data flow engine that processes all other data at Snowflake, enabling efficient transformation and extraction of information from unstructured data and combining it with structured data in the same execution flow.
A similar approach applies to the ingestion and transformation of unstructured data into Snowflake. Document AI provides a mechanism to convert unstructured data into a predefined, structured, data model through the same data loading mechanism as structured data, called Snowpipe.
Structured data
Snowflake supports a wide range of standard data types enabling effortless data migration from other data warehousing systems. In order to provide a uniform and consistent experience between different data formats, Snowflake provides a single and coherent type system that encompasses the Iceberg type system, as well as all native table formats.
This is possible due to the separation of logical and physical type systems as well as abstractions around persistent encoding of data. Logical types refer to the type system and behavior from the syntax and language semantic point of view, while the physical type system is how the query-execution engine encodes, stores and processes the types. The separation of the logical and physical type systems is an important design element of the data model that allows Snowflake to easily extend to new data types while supporting the Iceberg type system as well as many migration sources.
The separation between the physical types and their query-engine encoding from the the persistence layer enables Snowflake’s query engine and metadata to operate completely agnostic to the data storage format. The query-engine encodings are designed to mostly avoid memory copies and data transformation when loading blocks of data from on-disk persisted encodings, such as Parquet.
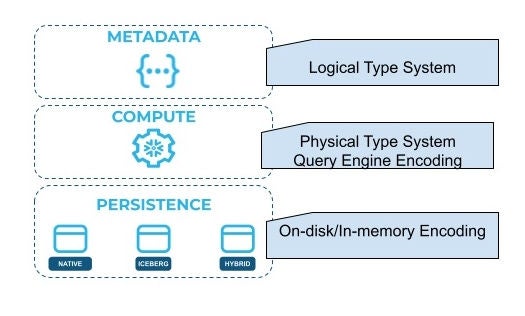
Vector data
Given the emerging use cases for embeddings in LLM-based data and AI applications, providing an efficient platform for storing and processing them is essential. Snowflake provides native support for vector data through a dedicated data type. The vector data type is designed to provide cost efficient and fast encoding of embeddings in memory or on disk. Additionally, the vector data type supports zero transformation cost to and from clients and user code interacting with the embeddings.
Native support for vectors is a critical part of enabling RAG and enterprise search use cases through Snowflake Cortex Search. A single pipeline generating, storing and retrieving embeddings, that runs on the Snowflake unified data flow query engine, enables hybrid vector- and keyword-based search without the need to export or mirror data in multiple backend systems.
In adding support for vectors in SQL, Snowflake provides a consistent experience, particularly in relation to nested structured data. An example would include seamless transition between arrays and vectors. Finally, Snowflake provides high-performance native SQL functions (e.g., distance functions) to operate on vector data.
Nested structured data
Snowflake supports nested structured data, which are used more broadly in modern data models to store complex data objects, denormalized relations and provide flexibility in machine-generated data through constructs such as maps and arrays. Snowflake follows three tenets in providing nested structured data support, by providing equivalent cost and performance between:
Storing and processing objects versus expanding the object into multiple individual columns
Storing and processing arrays versus flattening into separate rows
Storing and processing nested structured data and semistructured data that inherently have a fixed equivalent schema
These tenets are essential in making sure that the data model and schema are designed based on semantic requirements, such as validation on write vs read, as opposed to artificial cost and performance constraints. To achieve these goals, Snowflake takes a unique approach of using a unified representation of nested data in the data flow engine to represent both structured and semistructured data. Additionally, this representation enables the same vectorized columnar processing in the query engine as used with the top-level columns.
Another aspect of Snowflake design for nested structured data is that the in-memory representation and processing of such data is independent from the encoding used to persist the data. At the same time, the representation is designed to be extremely efficient in encoding and decoding the persistent representation, such as in Parquet support for Iceberg STRUCT type.
Geospatial data
Snowflake’s data type frameworks enable native support for specialized data types, such as geography and geometry. These data types are natively supported in the execution and storage engines through the same data-type framework as semistructured data, while providing native, domain-specific primitives, such as geography and geometry operators and joins.
Semistructured data
Snowflake has supported efficient storage and processing of semistructured data from day one as part of the query- and storage-engine design. Intelligent encoding, compression and shredding of semistructured fields are a key requirement for successful handling of semistructured data. Record shredding or striping refers to the process of representing individual fields within a record as top-level columns.
As mentioned earlier, the in-memory representation used to process semistructured data aligns with the vectorized columnar representation of data. The record shredding capability enables Snowflake to store and process individual fields of maps and arrays in the same way as top-level columns. Finally, Snowflake computes and stores hierarchical metadata, such as value constraints for various fields, and uses them for efficient pruning of the data. Similarly, search optimization indices are capable of processing and accelerating access to semistructured fields, similar to standard top-level columns.
The three elements described above enable Snowflake to provide the same efficiency and performance in storing and processing semistructured data with a slowly evolving schema, as seen with fully schematized structured data. Snowflake is an excellent choice for efficiently storing and processing large-scale machine-generated data, such as logs and events.
Universal metadata
Snowflake supports open data lake architecture using Iceberg tables, native Snowflake tables stored in a native columnar format, as well as Hybrid Tables stored in a combination of row-oriented and columnar encodings. This is done using a universal metadata layer that can be used to access and store data in all those various forms, and abstract away the differences from many components in the system. This is the key ingredient that allows Snowflake to enable the querying and writing of data with the same set of features and performance profile regardless of the table format.
Snowflake’s universal metadata layer enables seamless support for advanced optimization features, such as Dynamic Tables, Automatic Clustering or Search Optimization indices, in the exact same way, regardless of whether the data is stored in native Snowflake tables or in an Iceberg table. For example, Snowflake can create indices to prune micropartitions, and blocks within micropartitions, regardless of whether the micropartition is stored as a Parquet file or Snowflake native columnar file.
The main challenge in designing this layer is to find the right level of abstraction that works across all workloads. For example, it should be able to store micropartition-level statistics that encompass statistics available in various Parquet and Iceberg specifications, as well as both Snowflake native columnar and hybrid (row-oriented) storage statistics. It should support on-demand and extensible statistics that can work with internal and open source systems that provide auxiliary metadata.
The universal metadata layer is also a crucial building block that enables Snowflake Open Catalog, presenting a single pane of glass for all systems interacting with data through the Apache Polaris standard interfaces. Given the flexibility, performance and efficiency of the Snowflake metadata layer, Snowflake Open Catalog provides the best experience managing and working with open data lakes.
Storage tiers and infrastructure
The optimal storage of data heavily depends on the shape of the data and the workloads generating or consuming them (e.g., transactional or analytical). Snowflake leverages existing blob storage services on AWS, Azure and GCP. While blob storage is often a great choice for analytical workloads relying on the LSM architecture, Hybrid Tables introduce a new set of requirements. Foundation DB (FDB), which is the underlying technology behind Hybrid Tables, uses a row- and page-oriented storage format that is optimized for point lookups and fast updates. Latency is the overriding design concern for Hybrid Tables and that is why the most recent data uses local NVME to store the row-oriented FDB pages. However, Hybrid Tables also need to access historical versions of data, and that history is kept in blob storage.
This arrangement results in a tiered storage subsystem, with different tiers being responsible for different quality of service guarantees and for managing data in different formats that are best for the job at hand. We find that data tiering is crucial for cost and scalability. In addition, having access to tiered data enables us to implement an intelligent process of adaptive execution, in which we combine the properties of all available tiers to respond efficiently when large requests are submitted to storage. Finally, to maximize the benefits of data tiering, we implement automated intelligent transformation and placement processes that move data between tiers and layouts, depending on the access pattern and other properties of the data.
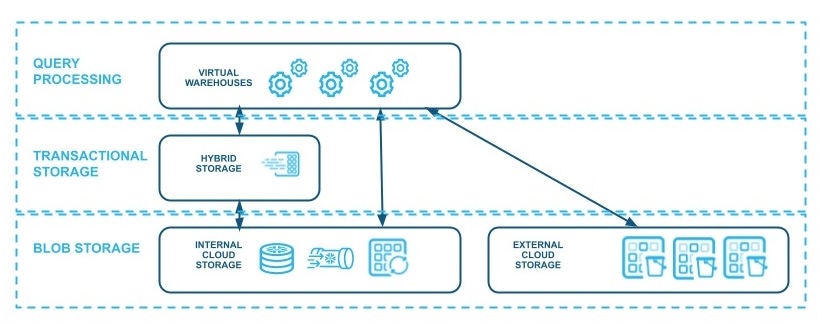
Disentangling the transactional storage layer, blob storage layer and query-processing layer is crucial in supporting workloads that need to access data in different layouts. Without this decoupling, it would be very difficult to seamlessly execute workloads taking advantage of the most optimal tier and layout, since the strong coupling of storage often limits the availability of storage tiers and layouts to particular compute nodes. Additionally, relying on existing cloud storage infrastructure instead of building new storage layers provides the following advantages:
This allows Snowflake customers to build on top of existing data lakes without paying any cost of moving or transforming data between different storage management systems.
This enables efficient integration with other data processing systems through zero-copy data ingestion and extractions.
By offloading many aspects of data delivery and replication, Snowflake makes data ingestion and extraction scalable and cost-efficient.
Snowflake is globally available in all regions where public cloud providers operate, enabling a global data cloud and sharing data sets across data applications in different regions.
Snowflake can provide customers with storage resource management choices, allowing customers to decide how to leverage their cloud resources for various workloads. This would not be possible without a layered storage architecture.
The storage layer interface in Snowflake is abstracted away from the compute layer, so that deploying Snowflake on a new storage cloud provider would not require any changes to the upper layers. Given the differences in the interfaces, behavior and performance profiles of storage systems provided by different cloud providers, such abstraction often requires careful design of a translation layer that can best utilize the available APIs. Optimizing Snowflake storage workloads given such interfaces requires designing the access path to work best with them. In some cases, close collaboration with Cloud Service Providers is essential to leverage the best performance and efficiency of the underlying system.
Data governance
Snowflake supports governance, access and discovery of all types of data, models, apps and more, through a unified framework called Snowflake Horizon. This governance framework is consistent across structured, semistructured and unstructured data, making application development and collaboration simple and secure across all data use cases.
A key building block for Snowflake Horizon is an object and artifact model that represents data and applications in a unified way. This enables role-based access control and policies across data regardless of the data type (structured or unstructured), format or source (Snowflake or externally managed). Since the data model is built based on the database and schema hierarchies, setting such policies can be done through the same user experience by the same data administrator. Additionally, the code components needed to enforce security, compliance and privacy policies can work independently of whether the data is structured or unstructured.
Features such as data quality monitoring and lineage graphs leverage this unified data object representation model to easily extend to new data types. Data discovery and sharing work similarly: As the new data types are introduced within the same object representation framework, these features seamlessly and automatically integrate with them.
The layered storage architecture described previously ensures that requirements like data residency are applied automatically. This allows new data model objects introduced in Snowflake to automatically meet necessary storage requirements, such as data residency enforcement through cloud storage guarantees.
Conclusion
Data representation, layout, tiering and storage layering are core components that enable the Snowflake AI Data Cloud to support heterogenous data shapes and types, specifically needed to power AI analytics in open data architectures. Snowflake processes unstructured and structured data through the same compute engine, opening numerous opportunities to build AI and data applications across heterogeneous data. It employs intelligent and novel ways to store and process both nested structured and semistructured data through the same set of abstractions, enabling support to efficiently store and process new data types, such as embeddings needed for AI applications.
While forming abstractions on data formats and access is common across cloud data management systems, Snowflake takes the concept further in unifying metadata and processing across formats, enabling seamless, uniform and comprehensive support for Iceberg and Snowflake native tables. Snowflake enables hybrid transactional and analytical workloads through a mix of storage tiers using different data layouts and storage infrastructure.
Finally, Snowflake enables customers to govern, access, share and discover data through a unified framework that takes advantage of the unified storage and data management capabilities that are built into the Snowflake architecture.
Authors


