Creating Automated Optimizations for Python User-Defined Functions with Snowpark's Parallel Execution

There are two common performance challenges when running Python-based user-defined functions (UDFs) generally across technologies:
Python global interpreter lock: The global interpreter lock prevents multiple threads from executing Python bytecodes at once, so multithreading cannot be used to take the advantage of multiple CPU cores. This may lead to a performance bottleneck.
Data skew: Data skew refers to an uneven distribution of data. When data is skewed, some nodes are overloaded with work, while others remain underutilized.
For example, a trivial example UDF like the following would take more than eight seconds, as it wouldn’t utilize all of the available resources well (one thread would process eight rows, one by one). We wanted to improve this automatically for Snowflake customers to get more performant execution and get the execution time down to two seconds.
-- Create the table
CREATE OR REPLACE TABLE example_table (
column1 INT
);
-- Insert 8 rows with the value 1
INSERT INTO example_table VALUES
(1), (1), (1), (1),
(1), (1), (1), (1);
-- UDF to simulate workload taking 1s per row by time.sleep(1)
create or replace function sleep(i int)
returns int
language python
RUNTIME_VERSION = '3.9'
handler = 'sleep_py'
as
$$
import time
def sleep_py(i):
time.sleep(1)
return i
$$;
-- Process 8 rows with pre-created UDF
select sleep(*) from example_table;
Snowpark's parallel execution
Snowflake already achieves great scalability by distributing workloads to multiple workers within a virtual warehouse, a cluster of compute resources in Snowflake. But to address the performance bottleneck of Python global interpreter lock, Snowpark also launches multiple Python interpreter processes to take advantage of multiple CPU cores in each worker when running custom UDFs, which can process the data in parallel. This multiple-Python-interpreter setup increases parallelism on a per-node basis. However, if data is unevenly distributed, it can lead to imbalanced workloads, preventing us from achieving optimal performance.
To address this issue, we introduced an additional optimization to redistribute the rows across parallel interpreters when Snowpark workloads are involved. During the execution stage, the source operator will redistribute the rows across all Python interpreter processes in different virtual warehouse nodes using a round-robin approach, ensuring full parallelism.
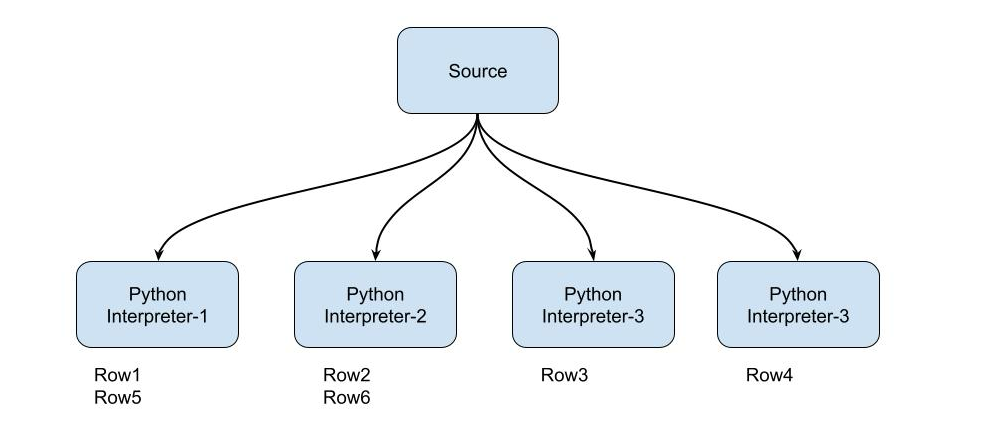
Redistribution is not free, and to achieve even distribution, the source operator may need to send rows to the Python interpreter processes in a remote node. This will increase the number of networking calls issued to the processes as well as the overhead to move data between different nodes. When this overhead exceeds the impact of data skew, performance is even worse with redistribution applied, demonstrating the need to evaluate the potential gains from redistribution for a particular workload, rather than apply it blindly.
So in order to reduce unnecessary overhead from redistribution, we also examine the per-row execution time for the workload from historical stats and define a threshold to determine whether row-level redistribution will be beneficial given potential redistribution overhead. Furthermore, we buffer the rows and asynchronously redistribute them to the Python interpreter processes when the receiver finishes the previous batch of work. This reduces the networking calls for redistributing rows, as the source operator generates output rows.
Other challenges and looking forward
Besides the extra overhead of redistributing rows, we don’t do row redistribution for certain scenarios because of potential data corruption:
The statement is DML or a Dynamic Tables refresh
The query plan tree has certain assumptions on the locality of rows
Also, the round-robin approach is not always the perfect redistribution mechanism — there is a certain level of variability depending on what the user-code operation is actually doing. In some cases, the amount of time it takes to process each row can vary significantly, so even if each Python interpreter process is processing the same number of rows, the execution time might differ on a per-row basis. In this case, the interpreter processes would require different times to complete processing the allocated rows, and fail to achieve optimal performance.
To address the above challenge, we are currently enhancing our redistribution algorithm to support more query patterns and further reduce the performance degradation caused by data skew processed via Snowpark UDFs.
Authors
