Dimensionnez vos analyses de texte non structuré avec une inférence de LLM par batch efficace

Le texte non structuré est partout en entreprise : avis clients, tickets d’assistance, transcriptions d’appels, documents. Les grands modèles de langage (LLM) transforment la façon dont nous extrayons la valeur de ces données en exécutant des tâches, de la catégorisation à la synthèse, et plus encore. Bien que l’IA ait prouvé qu’il était possible de discuter en temps réel dans un langage naturel avec des LLM, l’extraction d’informations à partir de millions d’enregistrements de données non structurées à l’aide de ces LLM peut changer la donne. C’est là que l’inférence de LLM par batch devient essentielle.
Dans cet article, vous aurez des informations sur les cas d'usage courants pour l'analyse de données textuelles à grande échelle. Vous découvrirez également pourquoi le déploiement de pipelines de LLM par batch peut être difficile et comment Snowflake a optimisé Snowflake Cortex AI pour l’inférence par batch via des fonctions SQL.
Quelles sont les tâches courantes d’inférence de LLM par batch ?
Différentes équipes d’une entreprise peuvent exploiter l’inférence de LLM par batch pour extraire des informations à partir d’importants volumes de données textuelles. Les équipes de veille client analysent les avis et les commentaires de forums pour identifier les tendances d’opinions, tandis que les équipes de support traitent les tickets pour découvrir les problèmes des produits et informer les lacunes dans une feuille de route produit. Parallèlement, les équipes d’exploitation utilisent l’extraction d’entités sur les documents pour automatiser les flux de travail et permettre un filtrage analytique basé sur les métadonnées. Voici quelques exemples de la façon dont différentes équipes peuvent utiliser des LLM pour extraire des informations à partir d’importants volumes de données textuelles non structurées :
Classification et balisage du texte : classement automatique des tickets d'assistance, des e-mails, des articles de presse ou des avis sur les produits en fonction des opinions, du sujet ou de l'urgence.
Extraction d’entités : extraction d’entités clés (noms, dates, lieux, données financières) à partir de contrats, de factures ou de dossiers médicaux pour transformer du texte non structuré en données structurées.
Analyse des opinions et des tendances : analyse des commentaires des clients, des réponses à une enquête ou des discussions sur les réseaux sociaux à grande échelle pour détecter des tendances, mesurer les opinions et éclairer les décisions commerciales.
Modération du contenu : analyse de jeux de données volumineux (publications sur les réseaux sociaux, journaux de chat, commentaires clients) pour détecter toute violation de politique, tout contenu préjudiciable ou tout problème de conformité réglementaire.
Résumé de document : générer des résumés concis pour d’importants volumes de rapports, de documents de recherche, de documents juridiques ou de transcriptions de réunions.
Préparation des documents à la RAG : ingestion, nettoyage et découpage des documents avant de les intégrer dans des représentations vectorielles, ce qui permet une récupération efficace et des réponses améliorées des LLM dans les systèmes de génération augmentée de récupération (RAG).
Qualité des données textuelles : validation de plusieurs champs de texte tels que les remplissages de formulaires en fournissant un contexte sur des combinaisons de saisie idéales, ce qui permet aux LLM de détecter les anomalies et les enregistrements incorrects pour améliorer la qualité des données.
Feature engineering : extraction, catégorisation et transformation de texte non structuré en features structurées, amélioration des modèles de machine learning avec un contexte et des informations enrichis.
Pourquoi des pipelines de LLM par batch efficaces sont importants
« Les LLM changent le lieu de travail » est bien plus qu'un simple slogan. Considérez ceci : catégoriser 10 000 tickets d’assistance prendrait environ 55 heures à votre employé le plus rapide (à raison de 20 secondes par ticket). Avec un pipeline de LLM optimisé, la même tâche prend quelques minutes. Il ne s’agit pas d’une amélioration incrémentielle, mais d’un gain d’efficacité transformateur, qui économise des milliers d’heures de travail et accélère considérablement les temps de réponse.
À mesure que les volumes de données augmentent et que l’automatisation de l’IA se développe, la rentabilité du traitement avec des LLM dépend à la fois de l’architecture système et de la flexibilité du modèle. Un système de traitement par batch efficace s’adapte de manière rentable pour gérer des volumes croissants de données non structurées. La possibilité de changer de LLM de façon flexible aide les entreprises à optimiser leurs coûts en dimensionnant les modèles pour chaque cas d'usage et en les mettant facilement à niveau à mesure que les modèles s'améliorent.
De plus, pour améliorer considérablement l’efficacité des technologies et des équipes, les entreprises doivent envisager les opportunités d’intégrer des pipelines de LLM aux workflows de données structurées existants. L’extension des investissements existants autour de la gestion, du traitement et de l’orchestration des pipelines simplifie l’architecture et réduit la complexité opérationnelle liée aux travaux d’intégration et de maintenance de l’infrastructure. Cette unification peut également permettre aux data engineers, qui gèrent déjà des pipelines structurés, d’intégrer et de maintenir facilement des workflows de données non structurées.
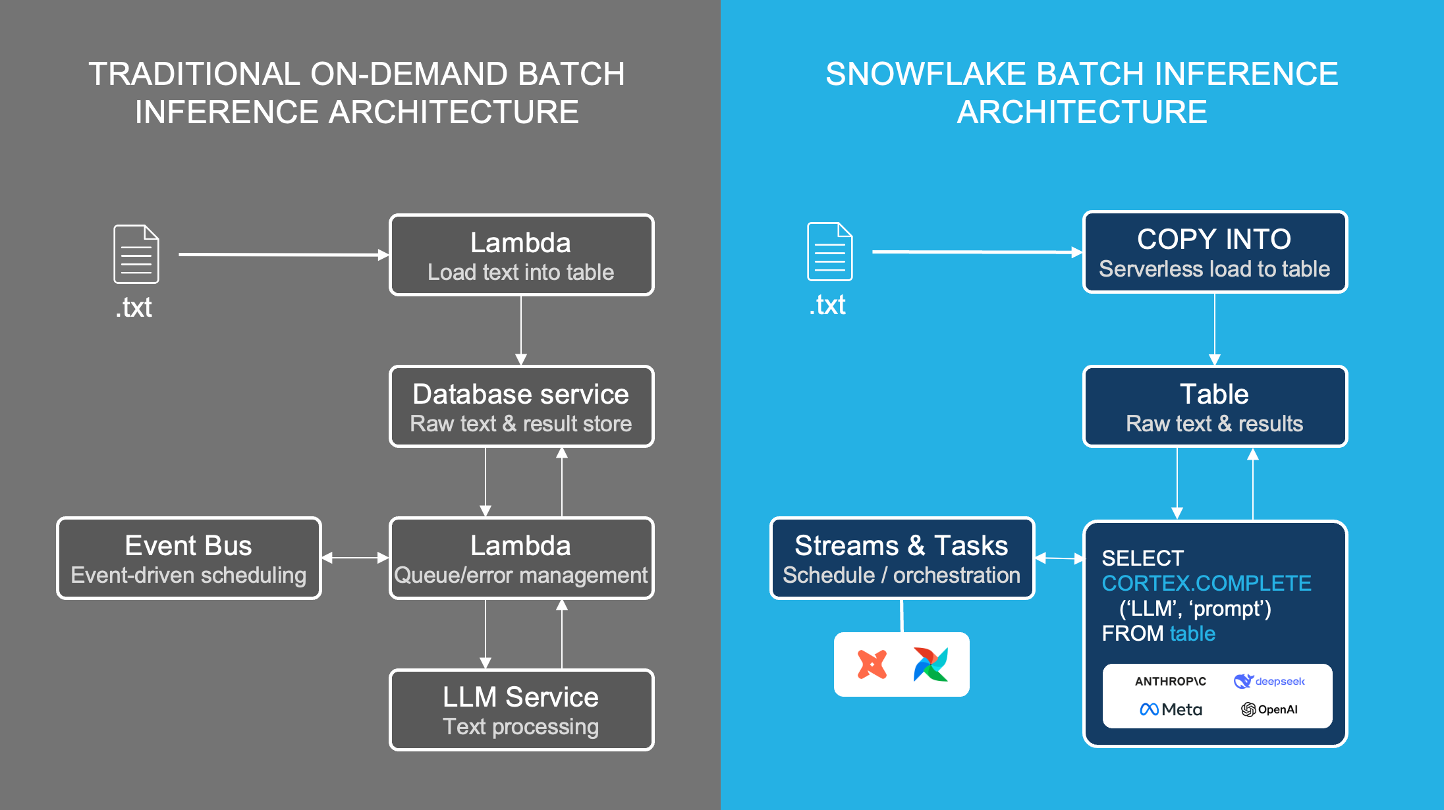
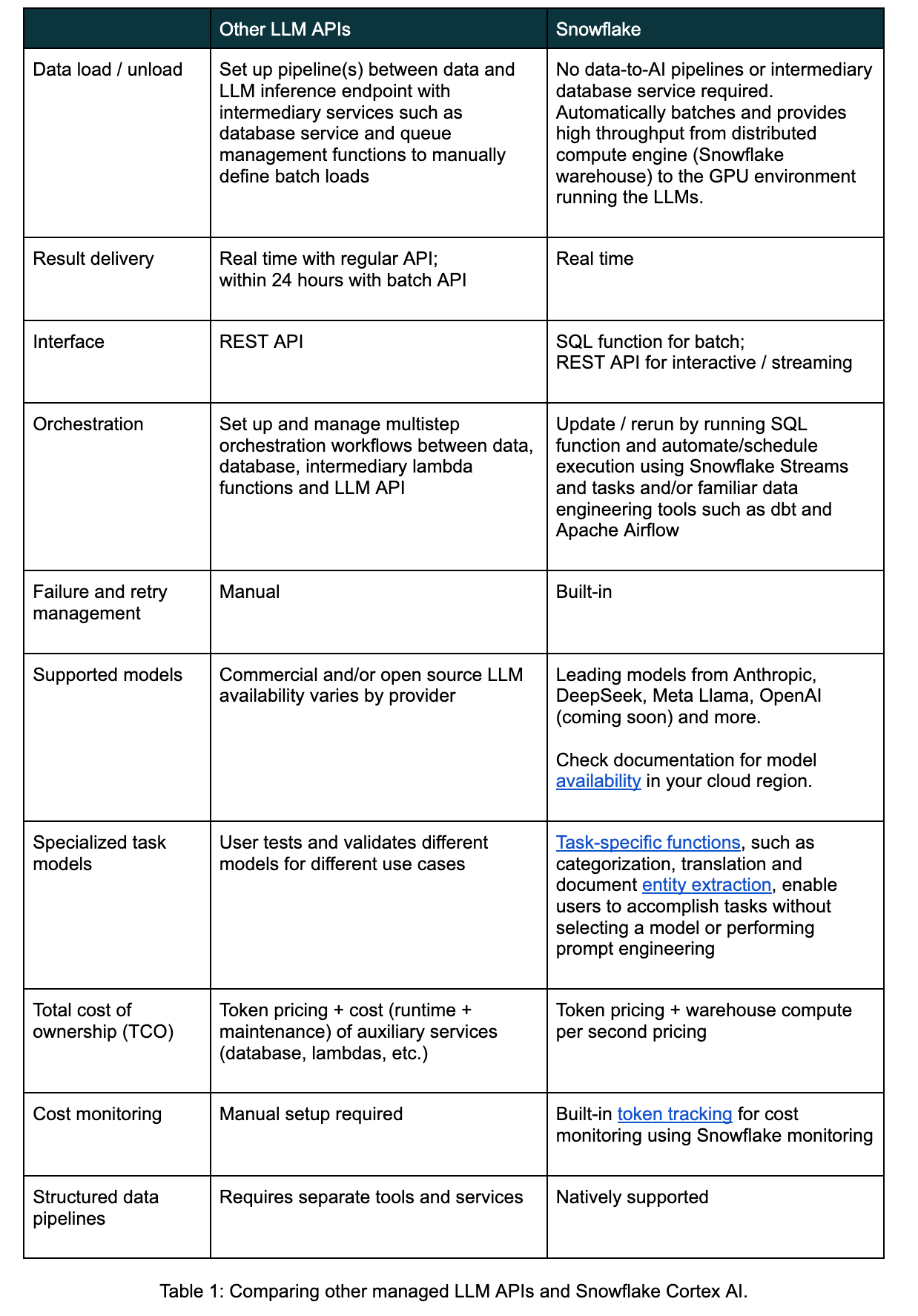
Exécutez efficacement des pipelines d’inférence par batch avec Cortex AI
Headset a commuté l’un de ses pipelines de catégorisation par batch, qui s’exécutait avec un grand fournisseur d’API LLM (Fireworks AI), et a vu l’exécution des tâches passer de 20 minutes à 20 secondes en utilisant la fonction d’inférence COMPLETE de Snowflake Cortex.
Grâce à la fonction COMPLETE de Snowflake Cortex, les développeurs peuvent exécuter une inférence de LLM par batch avec des fonctions SQL qui ne nécessitent pas de bases de données intermédiaires ou de lambda pour obtenir un traitement fiable et à haut débit avec un choix flexible de modèles.
Autres témoignages clients
En utilisant Snowflake, Nissan a accéléré de deux mois le calendrier de son projet pour une application de veille client qui analyse les opinions des clients à partir d’avis et de forums afin d’aider les concessionnaires à améliorer leurs offres de produits et services. Regardez le webinaire à la demande.
Skai a déployé un outil de catégorisation en seulement deux jours pour aider ses clients à obtenir de meilleures informations sur les modèles d’achat en créant des catégories qui ont du sens sur plusieurs plateformes d’e-commerce. Lisez l’étude de cas.
Retrouvez d’autres témoignages dans notre eBook sur la réussite client.
Premiers pas
Consultez ces ressources et suivez-nous pour les dernières actualités sur l’inférence serverless pour plus de types de données.
Auteurs

