Scalare l’analisi del testo non strutturato con un’efficiente inferenza LLM in batch

Il testo non strutturato è ovunque nel business: recensioni dei clienti, ticket di assistenza, trascrizioni delle chiamate, documenti. I large language model (LLM) stanno trasformando il modo in cui estraiamo valore da questi dati eseguendo attività che vanno dalla categorizzazione alla sintesi e altro ancora. Se da un lato l’AI ha dimostrato che con i LLM sono possibili conversazioni in tempo reale in linguaggio naturale, dall’altro estrarre insight da milioni di record di dati non strutturati utilizzando questi LLM può cambiare la vita. È qui che l’inferenza dei LLM batch diventa essenziale.
In questo articolo scoprirai i casi d’uso aziendali comuni per l’analisi dei dati di testo su larga scala. Scoprirai anche perché la distribuzione batch di pipeline LLM può essere difficile e in che modo Snowflake ha ottimizzato Snowflake Cortex AI per l’inferenza batch tramite funzioni SQL.
Quali sono i comuni processi di inferenza LLM batch?
Più team di un’organizzazione possono sfruttare l’inferenza batch dei LLM per estrarre insight da grandi volumi di dati di testo. I team di customer intelligence analizzano recensioni e commenti dei forum per identificare i trend del sentiment, mentre i team di assistenza elaborano ticket per scoprire problemi di prodotto e segnalare lacune nella roadmap di un prodotto. Nel frattempo, i team operativi utilizzano l’estrazione delle entità sui documenti per automatizzare i flussi di lavoro e abilitare filtri analitici basati sui metadati. Ecco alcuni esempi di come diversi team possono utilizzare i LLM per estrarre insight da grandi volumi di dati di testo non strutturati:
Classificazione e tagging: Classificare automaticamente ticket di assistenza, email, notizie o recensioni di prodotti in base al sentiment, all’argomento o all’urgenza.
Estrazione di entità: Estrazione di entità chiave (nomi, date, ubicazioni, cifre finanziarie) da contratti, fatture o cartelle cliniche per trasformare testo non strutturato in dati strutturati.
Sentiment e trend analysis: Analizzare feedback dei clienti, risposte a sondaggi o discussioni sui social media su vasta scala per rilevare i trend, misurare il sentiment e informare le decisioni aziendali.
Moderazione dei contenuti: Scansione di data set di grandi dimensioni (post di social media, log delle chat, feedback dei clienti) alla ricerca di violazioni delle policy, contenuti dannosi o problemi di conformità normativa.
Sintesi di documenti: Generazione di sintesi concise per grandi volumi di report, documenti di ricerca, documenti legali o trascrizioni di riunioni.
Preparazione RAG documenti: Ingestion, pulizia e chunking dei documenti prima di integrarli in rappresentazioni vettoriali, per un recupero efficiente e risposte LLM migliorate nei sistemi di Retrieval-Augmented Generation (RAG).
Qualità dei dati di testo: Convalidare più campi di testo, come i dati inseriti nei moduli, fornendo il contesto sulle combinazioni di input ideali, che consente ai LLM di rilevare anomalie e record errati per migliorare la qualità dei dati.
Feature engineering: Estrarre, categorizzare e trasformare testo non strutturato in funzionalità strutturate, potenziando i modelli di machine learning con contesto e insight arricchiti.
Perché sono importanti pipeline LLM batch efficienti
“I LLM stanno cambiando i luoghi di lavoro” è più di una semplice frase. Considera che: Per classificare 10.000 ticket di assistenza, anche il dipendente più veloce impiega circa 55 ore (a un ritmo di 20 secondi per ticket). Con una pipeline LLM ottimizzata, la stessa attività richiede minuti. Non si tratta di un miglioramento incrementale, ma di un aumento di efficienza trasformativo che fa risparmiare migliaia di ore di lavoro e accelera notevolmente i tempi di risposta.
Con la crescita dei volumi di dati e l’espansione dell’automazione basata sull’AI, l’efficienza dei costi nell’elaborazione con i LLM dipende sia dall’architettura del sistema che dalla flessibilità del modello. Un efficiente sistema di elaborazione batch scala a costi contenuti per gestire volumi crescenti di dati non strutturati. La possibilità di passare in modo flessibile da un modello all’altro aiuta le aziende a ottimizzare i costi dimensionando correttamente i modelli per ogni caso d’uso e semplificando l’aggiornamento quando i modelli migliorano.
Per creare significative efficienze tecnologiche e di team, le organizzazioni devono valutare le opportunità di integrare le pipeline LLM con i flussi di lavoro di dati strutturati esistenti. Estendere gli investimenti esistenti alla gestione, all’elaborazione e all’orchestrazione delle pipeline semplifica l’architettura e riduce la complessità delle operazioni di integrazione e manutenzione dell’infrastruttura. Questa unificazione può anche consentire ai data engineer, che già gestiscono pipeline strutturate, di integrare e mantenere facilmente flussi di lavoro di dati non strutturati.
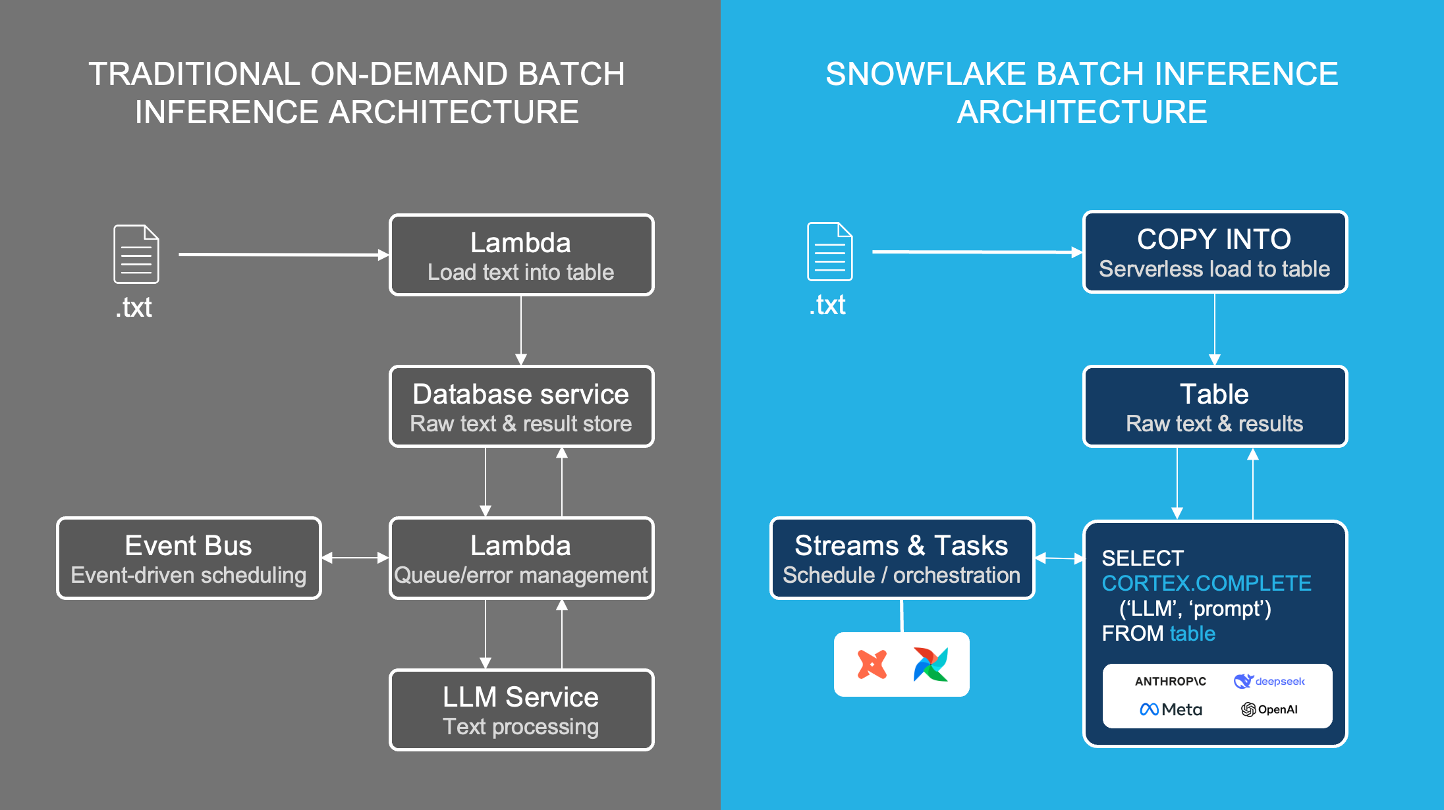
Eseguire in modo efficiente pipeline di inferenza batch con Cortex AI
Headset ha cambiato una delle sue pipeline di categorizzazione in batch, che era stata eseguita con un provider di inferenza API LLM (Fireworks AI), e ha visto l’esecuzione dei processi passare da 20 minuti a 20 secondi utilizzando la funzione di inferenza COMPLETE di Snowflake Cortex.
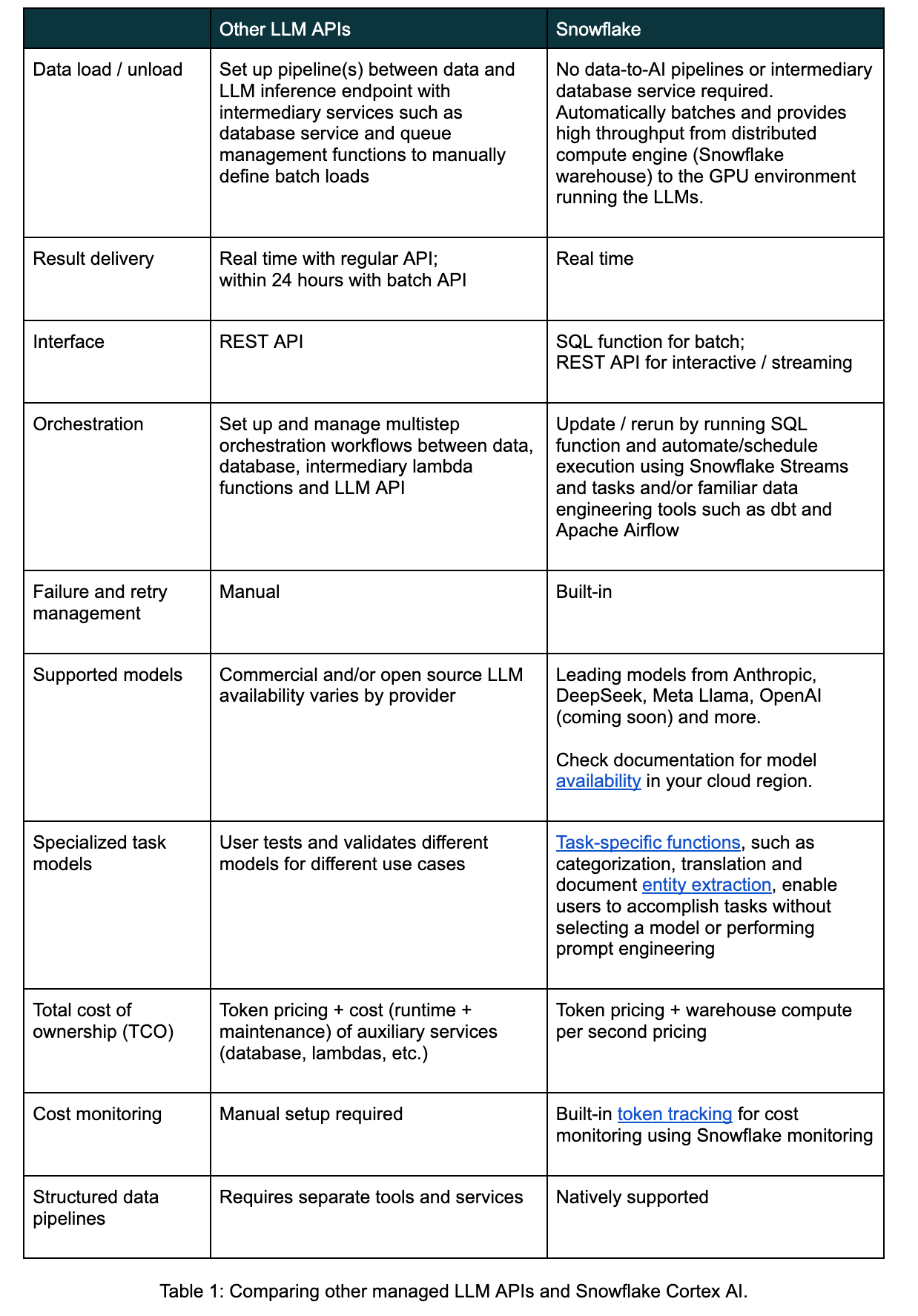
Utilizzando la funzione COMPLETE di Snowflake Cortex, gli sviluppatori possono eseguire l’inferenza LLM batch con funzioni SQL che non richiedono database intermediari o lambda per ottenere un’elaborazione affidabile ad alto throughput con scelta flessibile del modello.
Success story di clienti
Utilizzando Snowflake, Nissan ha accelerato di due mesi la tempistica di progetto per un’applicazione di customer intelligence che analizza il sentiment dei clienti su recensioni e forum per aiutare le concessionarie a migliorare la propria offerta di prodotti e servizi. Guarda il webinar on demand.
Skai ha distribuito uno strumento di categorizzazione in soli due giorni per aiutare i suoi clienti a ottenere insight migliori sui modelli di acquisto creando categorie sensate su più piattaforme di ecommerce. Leggi il case study.
Trova altre storie di successo di clienti nel nostro ebook.
Inizia subito
Dai un’occhiata a queste risorse e non perderti gli aggiornamenti sull’inferenza serverless per altri tipi di dati.
Articolo di

