Snowflake semplifica l’architettura dati, la governance e la sicurezza dei dati per accelerare il valore per tutti i workload

Oggi è facile che l’infrastruttura dati di un’organizzazione inizi a sembrare un labirinto, con un accumulo di soluzioni puntuali qua e là. Anche se alcune aziende riescono a combinare molti strumenti con pipeline complesse, non sarebbe meglio rimuovere alcuni passaggi? E se potessi semplificare i tuoi sforzi mentre crei un’architettura che meglio si adatta alle tue esigenze aziendali e tecnologiche?
Snowflake si impegna a fare proprio questo, aggiungendo continuamente funzionalità per aiutare i nostri clienti a semplificare la loro progettazione dell’infrastruttura dati. Che si tratti di unificare i dati transazionali e analitici con le Hybrid Tables, migliorare la governance di un lakehouse aperto con Snowflake Open Catalog o migliorare il rilevamento e il monitoraggio delle minacce con Snowflake Horizon Catalog, Snowflake sta riducendo il numero di “parti mobili” per offrire ai clienti un servizio completamente gestito e perfettamente funzionante.
In occasione di BUILD 2024, abbiamo annunciato diversi miglioramenti e innovazioni progettati per aiutarti a creare e gestire la tua architettura dati alle tue condizioni. Vediamo meglio.
Semplifica l’architettura dati per accelerare il valore
Per i casi d’uso ibridi transazionali e analitici, per i dati streaming e non strutturati, puoi creare soluzioni con Snowflake che richiedono meno parti in movimento, il che significa poter dedicare meno tempo e denaro alle configurazioni manuali e alla gestione dei silos e instradare queste risorse verso nuovi modi di utilizzare i dati.
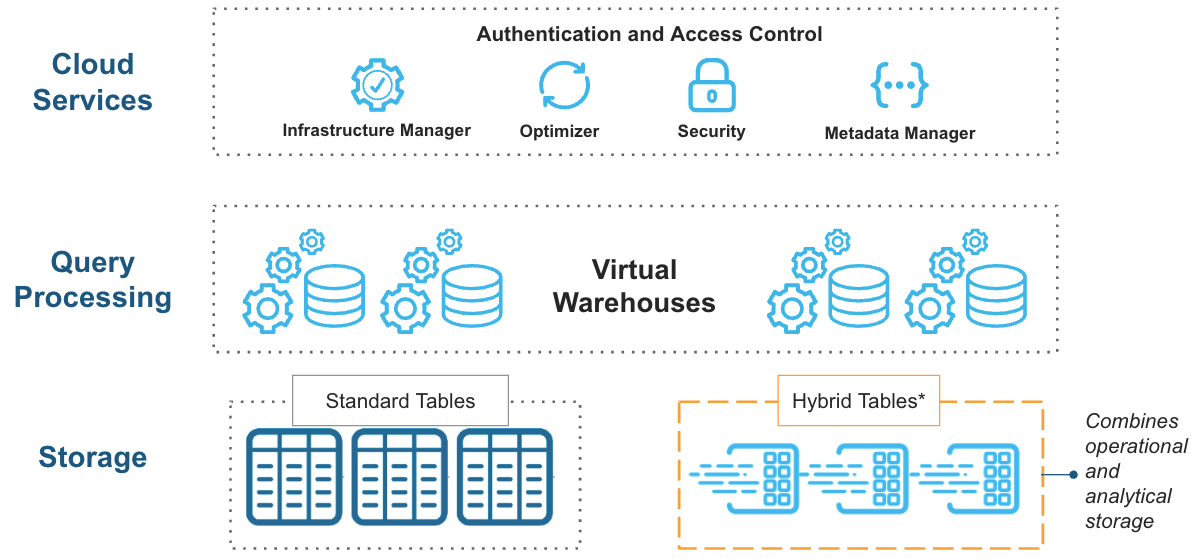
Unifica i workload transazionali e analitici in Snowflake per una maggiore semplicità
Molte aziende devono mantenere due database separati: uno per gestire i workload transazionali e l’altro per i workload analitici. Snowflake Unistore li consolida in un unico database per offrire agli utenti un’architettura drasticamente semplificata con meno spostamenti di dati e controlli di sicurezza e governance coerenti.
Unistore è reso possibile da Hybrid Tables (ora in GA per le regioni commerciali AWS), che consente letture e scritture rapide e a riga singola per supportare i workload transazionali. Con le operazioni rapide e ad alta concorrenza dei punti delle Hybrid Tables, puoi memorizzare lo stato delle applicazioni e dei flussi di lavoro direttamente in Snowflake, distribuire i dati senza reverse ETL e creare app transazionali leggere mantenendo un unico modello di governance e sicurezza per i dati sia transazionali che analitici, il tutto su un’unica piattaforma.
Carica i dati in modo più efficiente e gestisci i costi
Per i dati gestiti da Snowflake, stiamo introducendo funzionalità che aiutano ad accedere ai dati in modo semplice e conveniente. Con Snowpipe per Apache Kafka (presto in public preview su AWS e Microsoft Azure), un meccanismo “pull”, invece del connettore “push” esistente, consente di estrarre e caricare eventi Apache Kafka direttamente nel tuo account Snowflake senza ospitare il tuo cluster Kafka Connect. Questo riduce la complessità complessiva del preparare i dati in streaming per l’uso: Basta creare un’integrazione degli accessi esterni con la soluzione Kafka esistente.
SnowConvert è uno strumento di conversione del codice facile da usare che accelera le migrazioni su Snowflake del sistema legacy di gestione dei database relazionali (RDBMS). Oltre alle valutazioni gratuite e alle conversioni gratuite delle tabelle, SnowConvert ora supporta gratuitamente la conversione accurata delle viste del database da Teradata, Oracle o SQL Server.
Le nuove policy per il ciclo di vita dello storage (private preview) offrono un’altra opportunità di ridurre i costi eliminando automaticamente i record o archiviandoli a un livello low-cost quando corrispondono alle condizioni della policy personalizzata. Questo aiuta a ottimizzare lo storage mantenendo al contempo la conformità alle normative in modo semplice e scalabile.
Sblocca il valore dei documenti non strutturati con l’estrazione e l’integrazione automatizzate dei dati basate sull’AI
Ogni giorno aziende di ogni tipo sono inondate di documenti (fatture, ricevute, avvisi, moduli e altro), eppure l’acquisizione e l’utilizzo delle informazioni in essi contenute rimangono operazioni manuali, lunghe e soggette a errori. Con Document AI (in GA su AWS e Microsoft Azure), un workflow Snowflake completamente gestito che trasforma i documenti non strutturati in tabelle strutturate utilizzando un LLM integrato, Arctic-TILT, è possibile elaborare i documenti in modo intelligente e su vasta scala. Con l’opzione di ottimizzazione tramite un’interfaccia utente facile da usare, gli utenti aziendali e gli esperti di intelligenza artificiale senza esperienza possono essere pesantemente coinvolti nella creazione e nel perfezionamento dei modelli prima di chiamare i data engineer per implementare le pipeline. La Florida State University ha utilizzato Document AI per estrarre in modo efficiente i dati da PDF e fonti di terze parti, semplificando il controllo dei dati ed eliminando settimane di lavoro manuale.
Proteggi e comprendi meglio i tuoi account e data asset con Snowflake Horizon Catalog
Tra i principali vantaggi di Snowflake troviamo le funzionalità integrate di sicurezza, privacy, discovery e collaborazione leader del settore incluse nell’Horizon Catalog. Queste aiutano a proteggere e preservare la privacy del tuo account, degli utenti e dei data asset. Stiamo costantemente migliorando la nostra piattaforma per aiutare i nostri clienti a tenere il passo con le potenziali minacce.
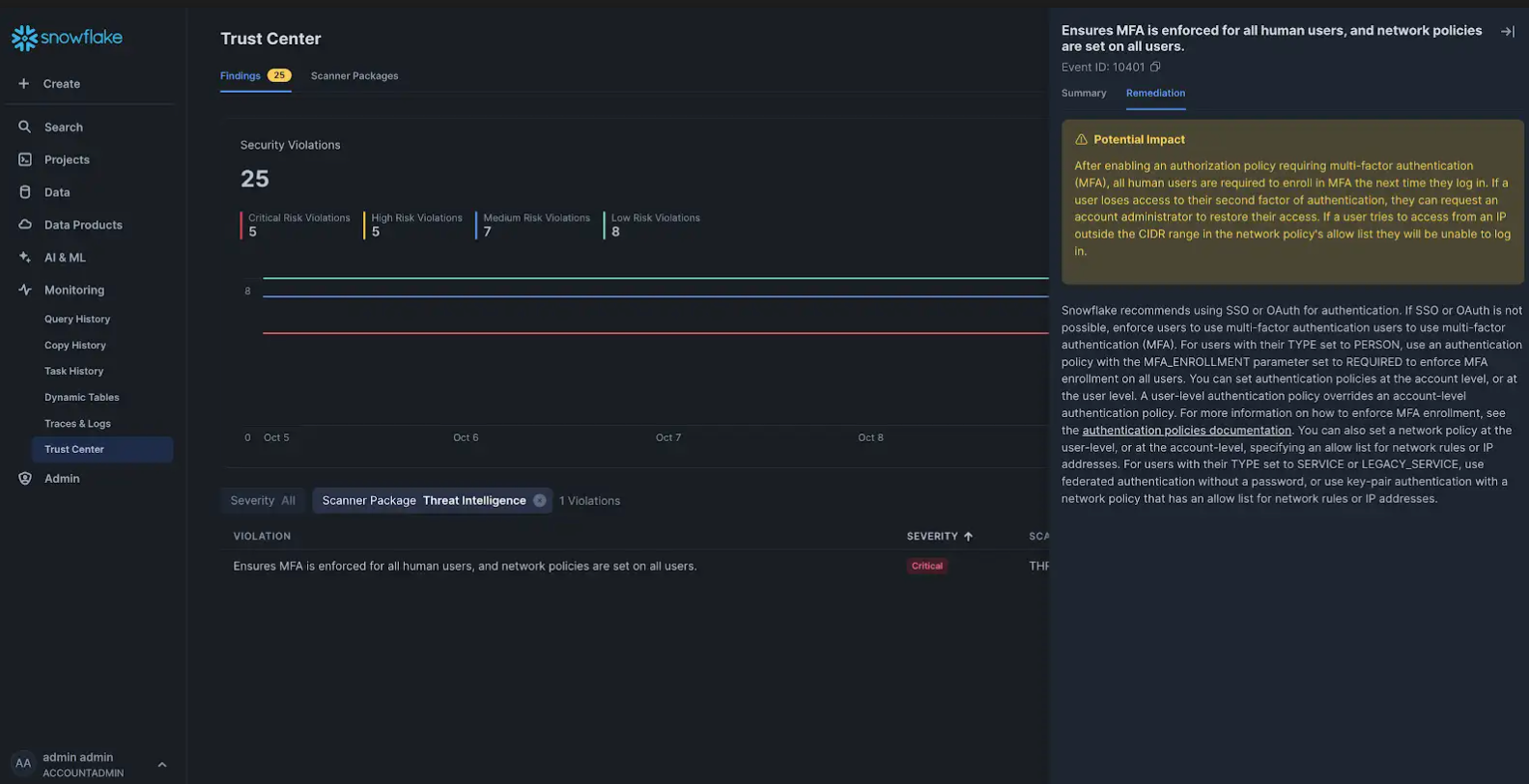
Previeni le minacce prima che si verifichino con funzioni di sicurezza avanzate e innovazioni del Trust Center
In un altro passo fondamentale verso l’eliminazione degli accessi password-only, Snowflake applica l’autenticazione a più fattori per tutti gli utenti umani di nuova creazione in qualsiasi account Snowflake. Stiamo anche attivando la funzione Leaked Password Protection (presto in GA), che verificherà e disabiliterà automaticamente le password degli utenti scoperte nel dark web. Questo fornisce una protezione integrata contro la divulgazione delle password e aiuta a limitare il potenziale di esfiltrazione dei dati. Gli utenti compromessi possono contattare gli amministratori degli account per reimpostare le password.
Per l’autenticazione API, Snowflake supporta Programmatic Access Tokens versatili e facili da sviluppare (presto in private preview) per semplificare l’esperienza di accesso alle applicazioni e migliorare la sicurezza includendo portata e scadenza di tali token. Inoltre, la nuova connettività Outbound Private Link (External Access è in GA su AWS e Azure; External Stage sarà presto in public preview su Azure e public preview su AWS; External Function è in GA su Azure) si connette a servizi esterni per i provider di servizi cloud e mantiene il traffico dati sempre all’interno della rete del provider di servizi cloud, senza mai attraversare la rete internet pubblica, per ridurre al minimo il rischio di esposizione ai dati e altre minacce informatiche.
I miglioramenti di Trust Center, un’interfaccia che aiuta a valutare e monitorare la postura di sicurezza del tuo account Snowflake, includono un nuovo pacchetto Threat Intelligence Scanner (in GA) per rilevare quali utenti (umani o di servizio) presentano un rischio, con chiari suggerimenti su come risolvere tali vulnerabilità. Guardando al futuro, Trust Center Extensibility (presto in private preview) consentirà ai clienti di aggiungere al Trust Center pacchetti di scanner personalizzati dei nostri partner, che sono disponibili come Snowflake Native App nel Marketplace Snowflake.
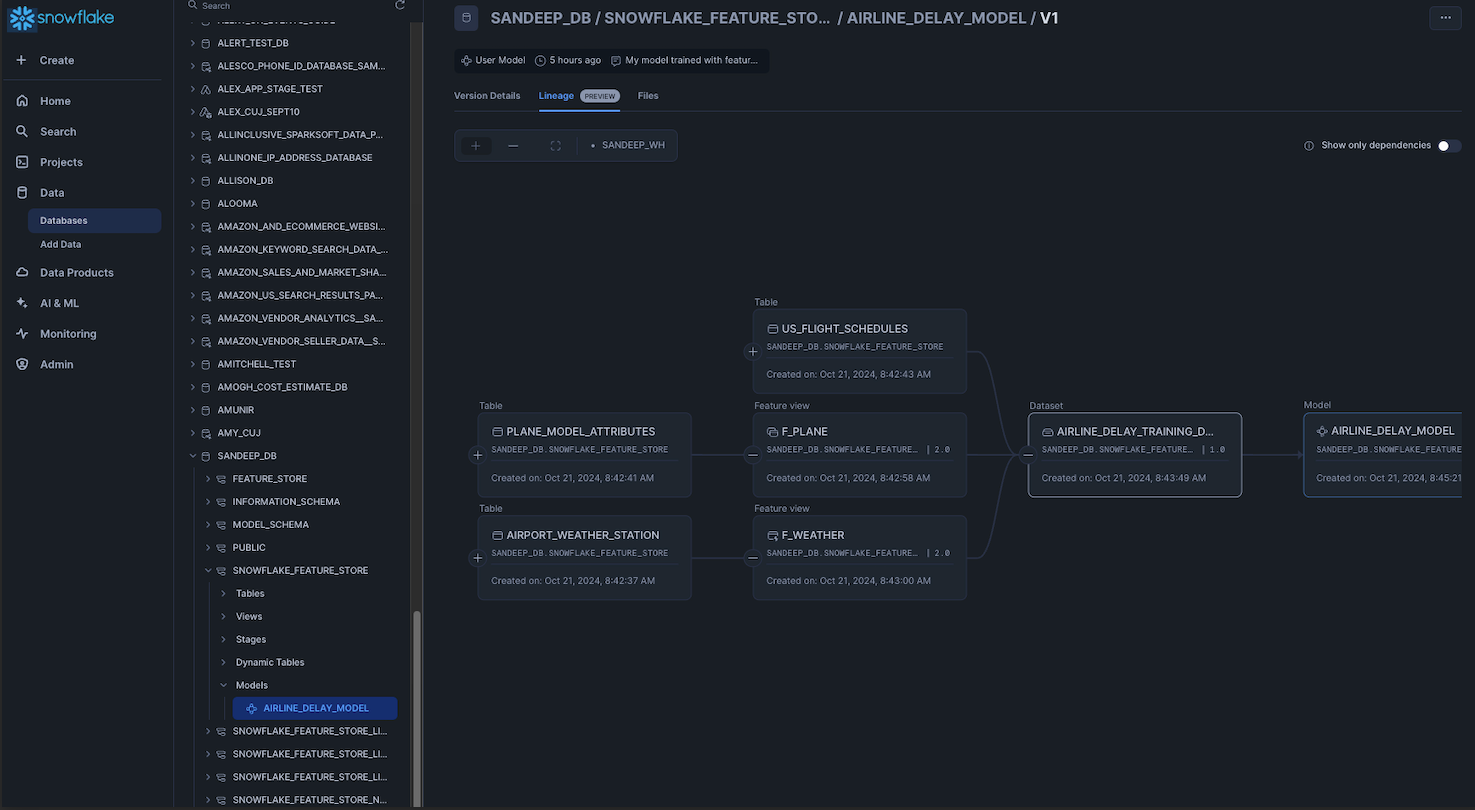
Implementa una migliore governance dei dati tracciando e gestendo facilmente i dati sensibili
La Lineage Visualization Interface (public preview) consente ai clienti di monitorare facilmente il flusso di dati e risorse ML con un’interfaccia interattiva in Snowsight. Questa nuova interfaccia consente ai clienti di vedere facilmente il potenziale impatto sugli oggetti a valle delle modifiche apportate a monte. Inoltre, sono possibili azioni in blocco per propagare tag e criteri a protezione delle colonne a valle. Per gli asset ML, i clienti possono tracciare il lineage end-to-end di funzionalità e modelli dai dati agli insight per migliorare la riproducibilità, la conformità e l’osservabilità semplificata.
Gli utenti possono anche automatizzare facilmente la classificazione, il tagging e il mascheramento dei dati sensibili in qualsiasi schema con Sensitive Data Auto-Classification (presto in public preview) tramite classificatori pronti all’uso o classificatori personalizzati creati utilizzando SQL.
I dati sensibili possono avere un enorme valore, ma spesso sono bloccati a causa dei requisiti di privacy. E se si potesse consentire a più persone di collaborare con i dati, estendendo l’ampiezza e la profondità dei dati sensibili analizzabili? Snowflake rende possibile tutto questo con policy di privacy differenziali (in GA), che riducono il rischio di identificazione o riprogettazione dei dati sensibili, e generazione di dati sintetici (public preview), che utilizzano dati di produzione originali per creare una replica per test e analisi.
Una nuova vista per la cronologia di tutti gli accessi dell’organizzazione (presto in public preview) offre a amministratori dei dati che condividono dati sensibili tra account all’interno della stessa organizzazione un record centralizzato di chi ha effettuato l’accesso a quali dati sensibili, semplificando la generazione di report di audit e fornendo la visibilità granulare necessaria per dimostrare la conformità ai requisiti normativi. Gli addetti ai dati possono anche impostare la funzione Request for Access (private preview) con una nuova proprietà di visibilità sugli oggetti insieme ai dati di contatto in modo da poter raggiungere facilmente la persona giusta a cui concedere l’accesso.
Semplifica il data engineering e la governance dei dati in un lakehouse aperto
Dal caricamento e l’integrazione fino alla trasformazione e la sicurezza, il processo di gestione di un data lake può essere impegnativo e costoso. Per le organizzazioni con architetture lakehouse, Snowflake ha sviluppato funzionalità che semplificano l’esperienza di creazione di pipeline e protezione dei data lakehouse con Apache Iceberg™, il formato tabellare open source leader.
Semplifica le pipeline bronze e silver per Apache Iceberg
Stiamo semplificando ulteriormente l’utilizzo delle Iceberg Tables con Snowflake in ogni fase.
Per l’ingestion di dati, puoi utilizzare Snowpipe Streaming per caricare i dati in streaming in Iceberg Tables a costi contenuti con un SDK (in GA) o un connettore Kafka basato su push (public preview). Per i casi d’uso batch e microbatch che aggiungono Iceberg nei data lake esistenti, stiamo introducendo nuove modalità di caricamento per COPY e Snowpipe (in GA) che aggiungono file Apache Parquet alle Iceberg Tables senza riscrivere i file. In precedenza noto come Parquet Direct durante la fase di private preview, questo nuovo parametro per COPY e Snowpipe consente di migliorare le prestazioni dei data lake legacy riducendo al contempo i costi di passaggio. Snowflake Delta Lake Direct (public preview) ti consente di accedere alle tue tabelle Delta Lake come Iceberg Tables per layer "bronze" e "silver" senza tutti i requisiti del formato universale (UniForm). Il supporto per l’aggiornamento automatico e la generazione di metadati Iceberg sarà presto disponibile in Delta Lake Direct.
Anche se nell’ecosistema Iceberg esistono altri strumenti che supportano le pipeline CDC (Change Data Capture), questi comportano complessità di orchestrazione per soddisfare i requisiti di aggiornamento. Le Snowflake Dynamic Apache Iceberg Tables (in GA questa settimana) semplificano notevolmente le pipeline CDC per Iceberg con un approccio dichiarativo: Scrivi la query del risultato desiderato, specifica un ritardo e lascia che sia Snowflake a occuparsi del resto. A breve, in private preview, potrai utilizzare le Iceberg Tables di cataloghi esterni come fonte per le Dynamic Iceberg Tables. Mentre Snowpark Python supporta la lettura e la scrittura su Iceberg Tables, ora è anche possibile creare Iceberg Tables con Snowpark Python (in GA). Infine, è possibile clonare Iceberg Tables (public preview) senza duplicare lo storage, per sperimentare con Iceberg Tables in modo sicuro e conveniente durante i test e lo sviluppo.
L’integrazione di Snowflake e Iceberg Tables nel tuo data lakehouse è semplificata da una serie di strumenti, tra cui il supporto per scrivere in Microsoft Fabric OneLake (public preview) come posizione di archiviazione. Utilizza questa guida quickstart dettagliata per scoprire come i clienti comuni possono utilizzare entrambe le piattaforme su un’unica copia dei dati, contribuendo così a ridurre i costi di storage e pipeline. Snowflake consente inoltre agli utenti di interrogare facilmente le Iceberg Tables da qualsiasi catalogo Iceberg REST (GA) o da qualsiasi Iceberg Table gestita esternamente che utilizzi merge-on-read (private preview). Per garantire che stiate interrogando le versioni più recenti delle vostre tabelle, potete aggiungere un’impostazione di aggiornamento automatico (presto in GA) alle vostre definizioni di integrazione delle tabelle e dei cataloghi Iceberg in SQL.
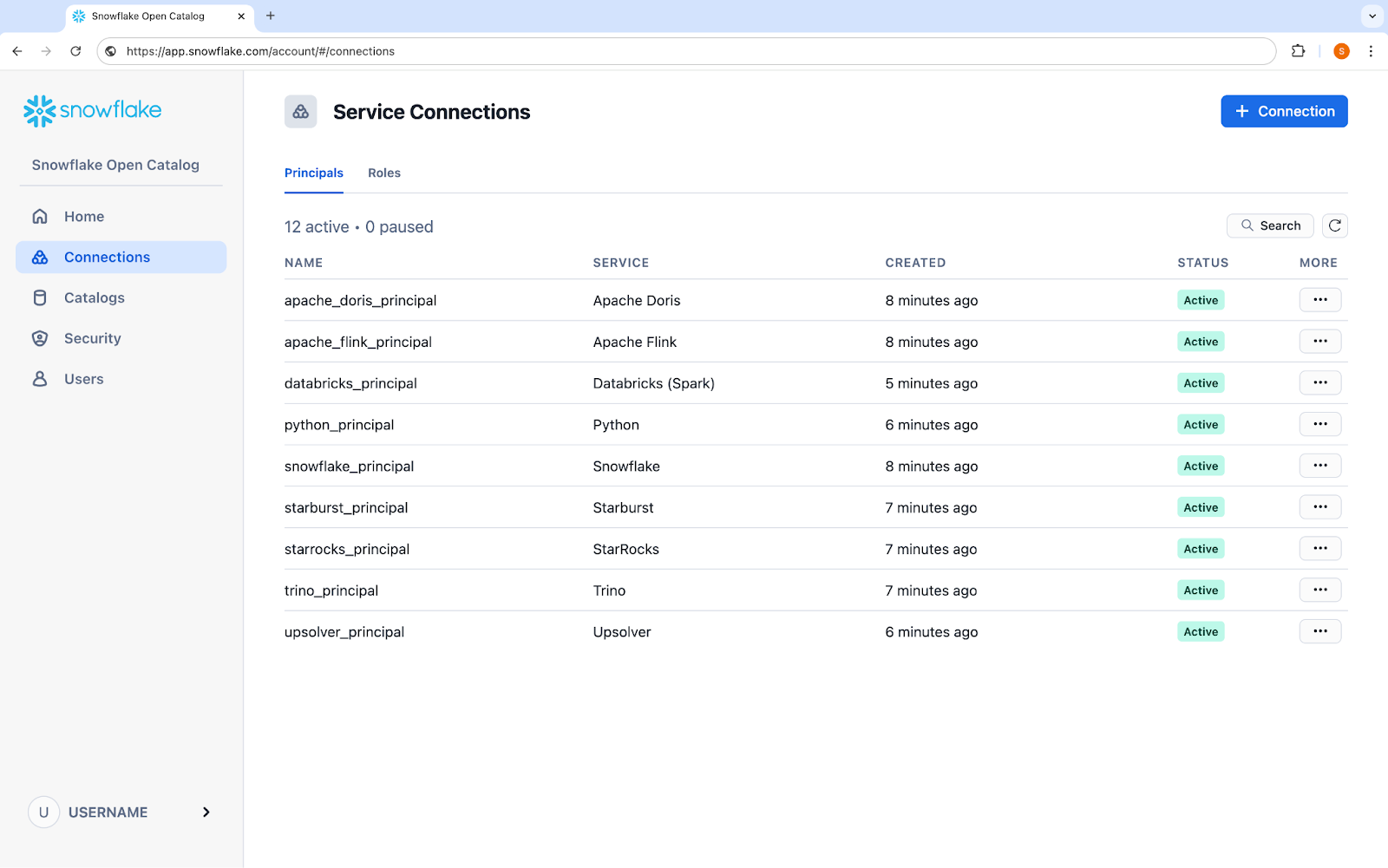
Collabora in modo semplice e sicuro con Snowflake Open Catalog, un servizio gestito Snowflake per Apache Polaris
A luglio 2024, Snowflake ha reso open source un catalogo per Apache Iceberg, ora noto come Apache Polaris™ (in incubazione), che consente l’interoperabilità tra molti motori su un’unica copia dei dati, senza copie o spostamenti di dati superflui. Snowflake Open Catalog, un servizio completamente gestito per Apache Polaris, è ora in GA e offre agli utenti tutti i vantaggi di Polaris: nessun vendor lock-in, flessibilità dei motori, sicurezza cross-engine, affidabilità, sicurezza, scalabilità e supporto che rendono il tutto facile da iniziare e sicuro da usare. Ora i team della tua organizzazione possono collaborare sui data lake in modo sicuro con controlli di accesso coerenti per molti motori, reader e writer, come Apache Flink™, Apache Spark™, Presto e Trino.
Per supportare ulteriormente la collaborazione e la business continuity, abbiamo anche introdotto il supporto Iceberg per funzionalità come la replica (private preview) e l’auto-fulfillment cross-cloud (private preview). Puoi replicare le Iceberg Tables gestite da Snowflake dagli account di origine a quelli di destinazione con il tuo object storage aggiungendo il database padre e il volume esterno a un gruppo di failover. Inoltre, semplicemente configurando un listing contenente una Iceberg Table gestita da Snowflake perché sia disponibile in più regioni, i clienti possono condividere queste tabelle con consumer in altri cloud e regioni.
Scopri di più
L’architettura dati non deve necessariamente essere un labirinto di soluzioni puntuali che non solo rallentano la produttività, ma minacciano la sicurezza e la governance. Con questi miglioramenti, Snowflake mira a semplificare ulteriormente la sua piattaforma unificata offrendo al contempo la flessibilità necessaria per consentire ai clienti di creare le architetture più adatte alle loro esigenze.
Per saperne di più su questi annunci e su come Snowflake aiuta le organizzazioni a utilizzare i dati alle loro condizioni, non perderti la presentazione di apertura di BUILD 2024 o le sessioni What’s New:
Articolo di
