SwiftKV di Snowflake AI Research riduce i costi di inferenza dei LLM Llama di Meta fino al 75% su Cortex AI
I large language model (LLM) sono al centro delle trasformazioni dell’AI generativa, guidando soluzioni in tutti i settori, dall’assistenza clienti efficiente all’analisi dei dati semplificata. Le aziende hanno bisogno di inferenza performante, conveniente e a bassa latenza per scalare le proprie soluzioni Gen AI. Tuttavia, la complessità e le esigenze di calcolo dell’inferenza dei LLM rappresentano una sfida. I costi di inferenza rimangono proibitivi per molti workload. È qui che entrano in gioco SwiftKV e Snowflake Cortex AI.
Le ottimizzazioni di SwiftKV sviluppate e integrate in vLLM dal team di ricerca AI Snowflake migliorano significativamente il throughput di inferenza dei LLM per ridurne i costi. I modelli Llama 3.3 70B e Llama 3.1 405B ottimizzati per SwiftKV, denominati Snowflake-LLama-3.3-70B e Snowflake-Llama-3.1-405B, ora disponibili per l’inferenza serverless in Cortex AI riducono i costi di inferenza fino al 75% rispetto ai modelli Llama Meta di base in Cortex AI non ottimizzati per SwiftKV. I clienti possono accedervi in Cortex AI tramite la funzione completa. Per continuare a consentire alle organizzazioni di portare in produzione le proprie app AI in modo efficiente e conveniente, stiamo valutando di portare le stesse ottimizzazioni ad altre famiglie di modelli disponibili in Snowflake Cortex AI.
SwiftKV
Vediamo in che modo SwiftKV raggiunge queste prestazioni. I casi d’uso aziendali spesso comportano prompt di input lunghi con output minimo (quasi 10:1). Ciò implica che la maggior parte delle risorse di calcolo viene consumata durante la fase di input (o precompilazione) della generazione della cache key-value (KV). SwiftKV riutilizza gli stati nascosti dei layer precedenti del transformer per generare una cache KV per i layer successivi. Questo elimina i calcoli ridondanti nella fase di precompilazione, riducendo notevolmente l’overhead di calcolo. Di conseguenza, SwiftKV riduce fino al 50% la capacità di calcolo di precompilazione mantenendo i livelli di precisione richiesti dalle applicazioni aziendali. Questa ottimizzazione aiuta a migliorare il throughput e a creare uno stack di inferenza più conveniente.
SwiftKV ottiene prestazioni di throughput superiori con perdita di precisione minima (vedere le tabelle 1 e 2). A tale scopo, combinando il rewiring del modello senza alterazione dei parametri con un fine‐tuning leggero per ridurre al minimo le probabilità di perdita di conoscenze. Utilizzando l’autodistillazione, il modello con rewiring replica il comportamento originale, ottenendo prestazioni quasi identiche. La perdita di precisione è limitata a circa un punto nella media di più benchmark (cfr. tabelle 1 e 2). Questo approccio chirurgico all’ottimizzazione garantisce che le aziende possano sfruttare le efficienze di calcolo di SwiftKV senza compromettere la qualità degli output Gen AI.


In base al nostro benchmarking, SwiftKV supera costantemente le implementazioni di cache KV standard e i tradizionali metodi di compressione della cache KV nei casi d’uso di produzione reali. Ad esempio, negli ambienti di produzione che utilizzano GPU di fascia alta come NVIDIA H100s, SwiftKV raggiunge un throughput fino a due volte superiore (figura 1) per modelli come Llama-3.3-70B. Questi miglioramenti si traducono in un completamento dei processi più rapido, una minore latenza delle applicazioni interattive (vedi tabella 3) e un notevole risparmio sui costi per le organizzazioni che operano su scala.
Prestazioni per caso d’uso
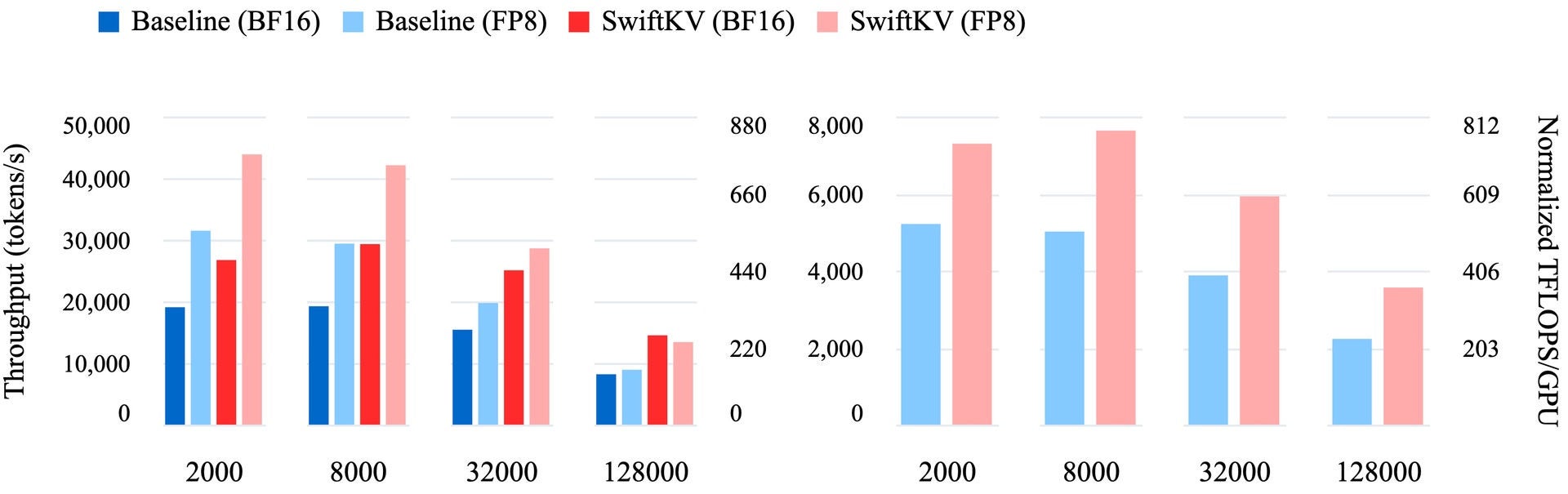
SwiftKV consente di ottimizzare le prestazioni in una gamma di casi d’uso. Per task di inferenza su vasta scala, come l’elaborazione di testo non strutturato (ad esempio sintesi, traduzione o analisi del sentiment), SwiftKV migliora il throughput combinato (figura 1), consentendo alle aziende di elaborare più dati in meno tempo. In scenari sensibili alla latenza, come chatbot o assistenti dell’AI, SwiftKV riduce fino al 50% il time-to-first token (vedi tabella 4), rendendo le esperienze utente più veloci e reattive. Inoltre, SwiftKV si integra perfettamente con vLLM senza modifiche significative per consentire un’ampia gamma di tecniche di ottimizzazione complementari, tra cui l’ottimizzazione dell’attenzione e la decodifica speculativa. Questa integrazione rende SwiftKV una soluzione versatile e pratica per i workload aziendali.


SwiftKV su Snowflake Cortex AI
L’introduzione di SwiftKV arriva in un momento critico per l’adozione delle tecnologie LLM da parte delle aziende. Con la crescita dei casi d’uso, le organizzazioni hanno bisogno di soluzioni che offrano sia miglioramenti immediati delle prestazioni che scalabilità a lungo termine. Affrontando direttamente i colli di bottiglia computazionali dell’inferenza, SwiftKV offre un nuovo percorso in avanti, consentendo alle aziende di sbloccare il pieno potenziale delle loro distribuzioni di LLM in produzione. Siamo entusiasti di fornire l’innovazione SwiftKV sui modelli Llama con il lancio di Snowflake-Llama-3.3-70B e Snowflake-Llama-3.1-405B con inferenza a una frazione del costo (rispettivamente 75% e 68% in meno). I modelli Llama derivati da Snowflake sono un fattore di svolta per le aziende che vogliono scalare l’innovazione con la Gen AI in modo semplice ed economico.
SwiftKV open source
Come iniziare: Training su SwiftKV in questo quickstart.
Poiché SwiftKV è completamente open source, puoi anche distribuirlo da solo con checkpoint del modello in Hugging Face e inferenza ottimizzata su vLLM. Puoi trovare ulteriori informazioni nel nostro blog sulla ricerca SwiftKV.
Stiamo anche creando pipeline di distillazione delle conoscenze tramite ArcticTraining Framework open source in modo che tu possa creare i tuoi modelli SwiftKV per le tue esigenze aziendali o accademiche. ArcticTraining Framework è una potente libreria post-addestramento per ottimizzare la ricerca e lo sviluppo. È progettato per facilitare la ricerca e prototipare nuove idee per il post-addestramento senza farsi sopraffare da complessi livelli di astrazione o generalizzazioni. Offre una pipeline di generazione di dati sintetici di alta qualità e facile da usare e un framework di addestramento scalabile e adattabile per l’innovazione algoritmica, oltre a una ricetta pronta all’uso per addestrare i propri modelli SwiftKV.
Conclusione
Con la continua espansione dell’innovazione basata sulla Gen AI in tutti i settori e i casi d’uso, ottimizzazioni come SwiftKV sono fondamentali per portare l’AI agli utenti finali in modo efficiente ed economico. Ora disponibile come open source, SwiftKV rende l’AI generativa di livello enterprise più veloce e meno costosa da eseguire. Andando oltre, lanceremo anche modelli Llama ottimizzati con SwiftKV in Snowflake Cortex AI. Con i modelli Snowflake-Llama-3.3-70B e Snowflake-Llama-3.1-405B, i clienti registrano costi di inferenza inferiori fino al 75%. Li stiamo aiutando a creare soluzioni Gen AI convenienti e ad alte prestazioni.
Articolo di




