効率的なバッチLLM推論による非構造化テキスト分析の拡張

非構造化テキストは、顧客レビュー、サポートチケット、通話記録、ドキュメントなど、ビジネスのあらゆる場所で見られます。大規模言語モデル(LLM)は、分類や要約などのタスクを実行することで、データから価値を抽出する方法に革命をもたらしています。AIは、LLMを使用した自然言語でのリアルタイムの会話が可能であることを証明しましたが、さらに、こうしたLLMを使用して何百万もの非構造化データレコードからインサイトを抽出できるようになったことは、世界を一変させる可能性を秘めています。そして、そのためにはバッチLLM推論が不可欠です。
この記事では、大規模なテキストデータ分析の一般的なビジネスユースケースについての知見をご紹介します。また、バッチLLMパイプラインの導入が難しい理由と、SnowflakeがどのようにSnowflake Cortex AIをSQL関数によるバッチ推論向けに最適化したかについても説明します。
バッチLLM推論の一般的なジョブ
組織内のさまざまなチームが、バッチLLM推論を活用して大量のテキストデータからインサイトを抽出できます。顧客インテリジェンスチームは、レビューやフォーラムのコメントを分析してセンチメントのトレンドを特定することが可能です。一方で、サポートチームは、チケットを処理して製品の問題点を明らかにし、製品ロードマップのギャップを特定できます。また、オペレーションチームは、ドキュメントのエンティティ抽出を使用してワークフローを自動化し、メタデータドリブンな分析フィルタリングを利用できるようになります。この他にもさまざまな方法で、チームはLLMを使用して大量の非構造化テキストデータからインサイトを抽出できます。以下に、その一部を例として挙げます。
テキスト分類とタグ付け:センチメント、トピック、緊急度に基づいて、サポートチケット、Eメール、ニュース記事、製品レビューを自動的に分類する
エンティティの抽出:契約書、請求書、医療記録から主要なエンティティ(名前、日付、所在地、財務数値)を抽出し、非構造化テキストを構造化データに変換する
センチメントおよびトレンド分析:顧客からのフィードバック、アンケートの回答、ソーシャルメディアでのディスカッションを大規模に分析し、トレンドの検出、センチメントの測定、ビジネス意思決定への情報提供を行う
コンテンツのモデレーション:大量のデータセット(ソーシャルメディアへの投稿、チャットログ、顧客フィードバック)をスキャンし、ポリシー違反、有害なコンテンツ、規制コンプライアンスの問題を検出する
ドキュメントの要約:大量のレポート、研究論文、法的文書、会議録の簡潔な要約を生成する
RAGのためのドキュメント準備:ドキュメントをベクトル表現に埋め込む前に取り込み、クリーニング、チャンキングを実行することにより、拡張検索生成(RAG)システムでの効率的な検索と強化されたLLM応答を実現する
データ品質:理想的な入力の組み合わせについてのコンテキストを提供することで、フォーム入力などの複数のテキストフィールドを検証する。これにより、LLMは異常や誤ったレコードを検出できるようになり、データ品質の改善につながる
特徴量エンジニアリング:非構造化テキストを抽出、分類して、構造化された特徴量に変換し、エンリッチされたコンテキストとインサイトを使用して機械学習モデルを強化する
バッチLLMパイプラインの効率化が重要な理由
「LLMが職場を変える」という言葉は、単なるキャッチコピーではありません。たとえば、10,000件のサポートチケットを分類するには、最速の従業員でも約55時間かかります(1件あたり20秒)。最適化されたLLMパイプラインでは、同じタスクに数分しかかかりません。これは漸進的な向上ではなく、何千時間もの労働時間を節約し、応答時間を劇的に短縮する革新的な効率性の改善です。
データ量が増え、AIの自動化が拡大するにつれて、LLMによる処理のコスト効率は、システムアーキテクチャとモデルの柔軟性の両方に依存するようになります。効率的なバッチ処理システムは、コスト効率の良い方法でスケーリングを行い、増え続ける非構造化データを処理します。LLMを柔軟に切り替えられれば、ユースケースごとにモデルを適切なサイズにし、モデルの改善に合わせて簡単にアップグレードできるようになるため、企業はコストを最適化できます。
また、テクノロジーとチームの効率を大幅に高めるためには、LLMパイプラインを既存の構造化データワークフローと統合する機会を検討する必要があります。パイプライン管理、処理、オーケストレーションに関連する既存の投資を拡大することで、アーキテクチャが簡素化され、統合やインフラストラクチャのメンテナンス作業に由来する運用の複雑さが軽減されます。この統合を通じて、構造化パイプラインをすでに管理しているデータエンジニアも、非構造化データワークフローを簡単にオンボーディングして維持できるようになるというメリットを得られます。
Cortex AIを使用したバッチ推論パイプラインの効率的な実行
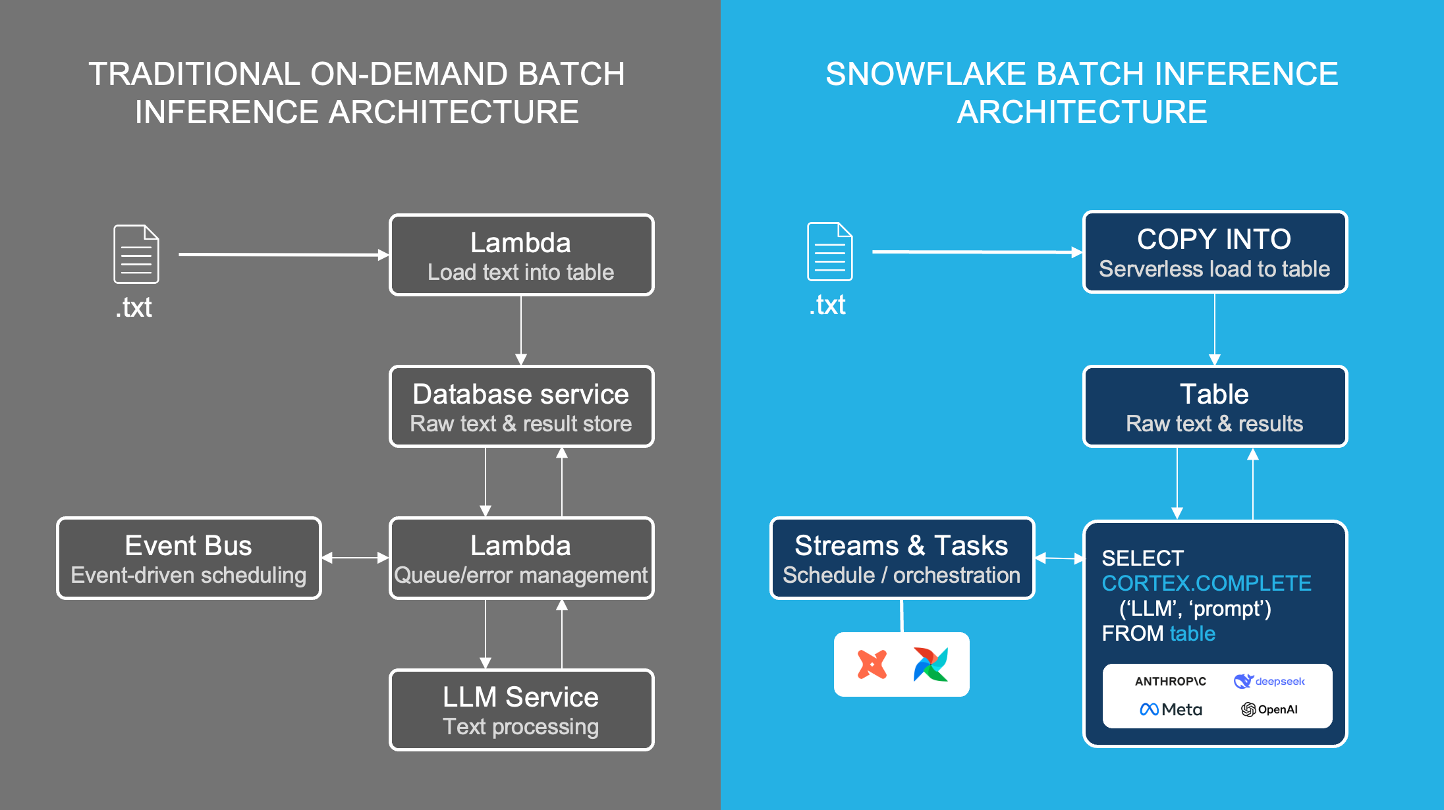
Headsetは、これまで大手のLLM API推論プロバイダー(Fireworks AI)で実行していたバッチ分類パイプラインの一つを切り替えて、Snowflake CortexのCOMPLETE推論関数を使用したことで、ジョブの実行時間を20分から20秒に短縮しました。
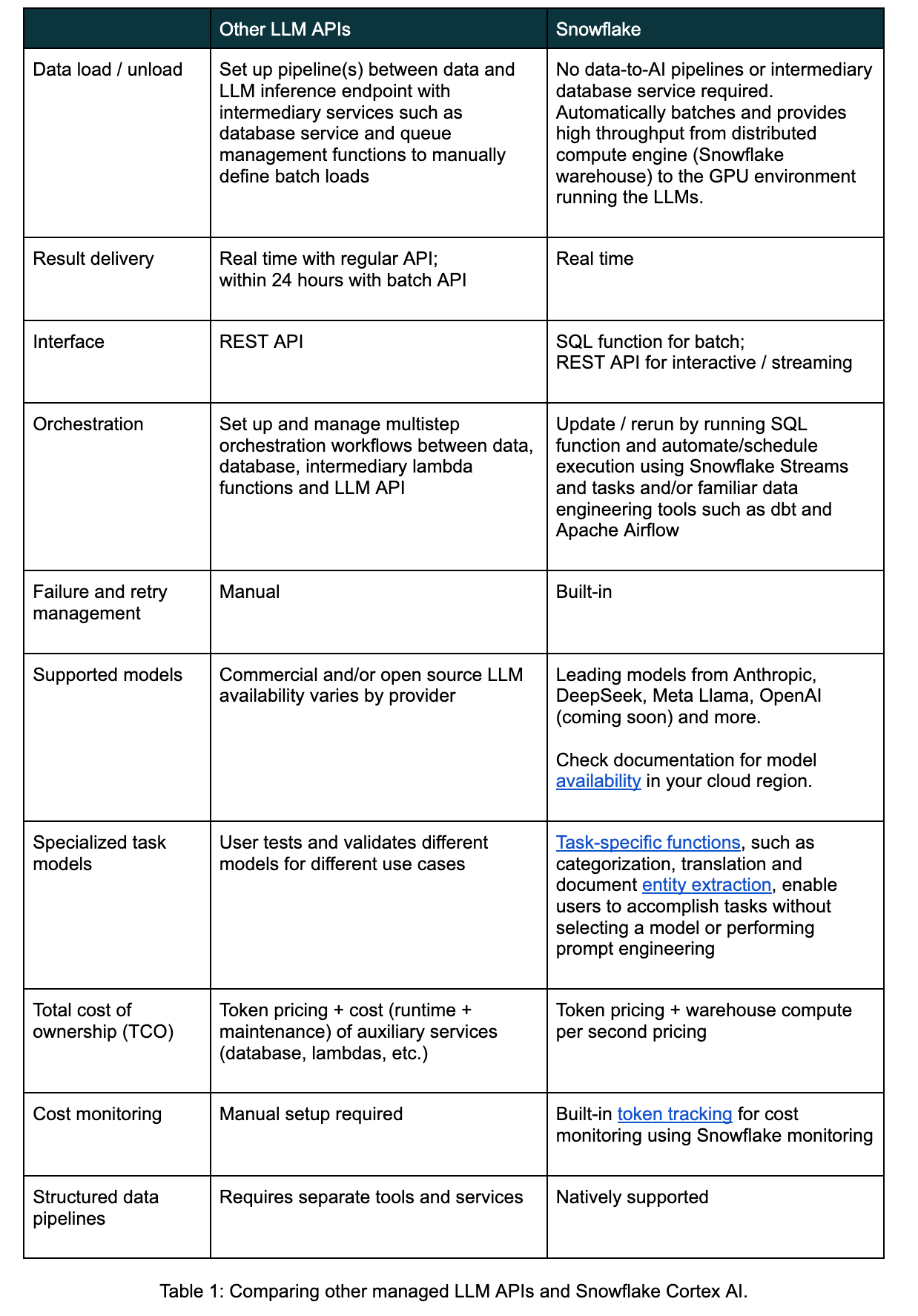
開発者は、Snowflake CortexのCOMPLETE関数を使用することにより、中間データベースやラムダを必要としないSQL関数でバッチLLM推論を実行し、柔軟なモデル選択によって信頼できる高スループットの処理を実現できます。
お客様のサクセスストーリー
日産は、Snowflakeを使用することによって、レビューやフォーラムから得た顧客のセンチメントを分析してディーラーの製品とサービス提供を強化する、顧客インテリジェンスアプリケーションのプロジェクトの期間を2か月短縮しました。オンデマンドウェビナーをご覧ください。
Skaiは、分類ツールをわずか2日間で展開し、複数のEコマースプラットフォームにまたがって意味のあるカテゴリを構築することによって、顧客が購買パターンのより優れたインサイトを得られるようにしました。ケーススタディをご覧ください。
その他のお客様のサクセスストーリーについては、eBookでご確認いただけます。
始める
以下のリソースでは、その他のデータタイプのサーバーレス推論に関する最新情報を確認できます。
著者

